1. Introduction to functional programming
1.1 Introduction
What does computing mean?
Roughly, to transform information from an implicit into an explicit form.
But this notion means nothing unless we make it precise, formal, by defining
a computational model.
What is a Computational model?
A particular formalization of the notions connected to the concept of
"computing".
The rather vague concept of computing can be formalized in several
different ways, that is by means of several
different computational models:
the Lambda-calculus, the Turing machine, etc.
"To program" means to specify a particular computation process, in
a language based on a particular computational model.
Functional programming languages are based on the Lambda-calculus
computational model.
Imperative programming languages are based on the Turing-machine
computational model.
The fundamental concepts in imperative programming languages (coming
from the Turing Machine model) are:
- store
- variable - something
it is possible to modify ("memory cell")
- assignment
- iteration
In functional programming these concepts are absent (or,
in case they are present, have a different meaning).
Instead, in it we find:
- expression
- recursion -
different from the notion of iteration
- evaluation -
different from the notion of execution:
- when
we evaluate a mathematical expression we do not modify anything.
- variable - intended
in a mathematical sense:
- unknown entity
- abstraction from a
concrete value
1.2 Functional programming
A program in a functional language consists in a set of function definitions and an expression (usually formed using the defined functions).
The Interpreter of the
language evaluates this expression by means of a discrete number of
computation steps, making its meaning explicit (as pointed out before,
during a computation, nothing is actually created, but
- a fact extremely clear in functional programming -
the representation of the information is "transformed".)
A function definition in functional programming is not
simply a means to uniquely identify a mathematical function on a
domain of objects.
Example: a mathematical definition of two functions
f: R
-> R , g: R -> R
f '' - 6g' = 6 sen x
6g'' + a2 f ' = 6 cos x
f(0) = 0, f '(0) = 0, g(0) = 1, g'(0) = 1
This set of equations precisely identify two precise f and g.
In the above example f and g are uniquely identified by the set of
differential equation, but such a definition is not useful from a
computational point of view.
A function definition in a functional programming language, instead,
has also to show how to compute (evaluate) the defined function on a given argument.
Example: function definition in Scheme and in Haskell
(define Inctwo (lambda (n) (+ n 2)))
Inctwo n = n + 2
The evaluation of the application of a (user-defined) function to an argument
consists in evaluating the expression consisting in the body of the function in which the formal
parameter is replaced by the actual parameter (the argument).
To evaluate an expression means to first
look for a sub-expression which is the application of a function to some
arguments and then to evaluate such an application.
In this way, in a sense, the meaning of the whole expression is made
more and more explicit.
Example: evaluating (Inctwo 3)
Inctwo is a user defined
function, and it is applied to an argument, so we take the body of the
function, replace the formal parameter n by the actual parameter 3, obtaining
3+2, and then we evaluate 3+2 obtaining 5
In the example above we have seen
two kinds of computational steps from Inc 3
to 5. In the first one we have
simply substituted in the body of the function the formal parameter by the
actual parameter, the argument, and in the second one we have computed a
predefined function. We shall see that the essence
of the notion of computation in functional programming is indeed embodied by
the first type of computational step. The simple operation of replacing the
arguments of a function for its formal parameters in its body contains
all the computing power of functional
programming. Any sort of
computation in functional programming could indeed be defined in terms of this
one. We shall see this later, when we shall represent this sort of
computational step with the beta-reduction rule in the lambda calculus and we
shall see that, if one wish, any
possible computation can be defined in terms of this beta-rule.
When we evaluate an expression there are sometimes more than one sub-expression one can choose and hence different possible evaluation paths
can be followed. An evaluation strategy is a policy enabling to decide on which
sub-expression we shall perform the next evaluation step. Some evaluation
strategies could lead me in a never-ending path (this fact is unavoidable); but
I would like to be sure that all finite path do lead me to the very same value
(this will be guaranteed by the Confluence Theorem of the Lambda-calculus).
Example: In Haskell
inf = inf
// definition of the value inf
alwayseven x =
7 // definition of the function
alwayseven
alwayseven inf
// expression to be evaluated
Two possible choices in the evaluation of alwayseven
Inf:
- We evaluate inf first
(the evaluation strategy of Scheme).
- We evaluate
alwayseven inf first (the
evaluation strategy of Haskell, a lazy language).
case 1. Replace inf
by inf => we go on endlessly
case 2. Replace alwayseven inf by 7 => we terminate in a single step.
One of the distinguishing features in a programming language is
the evaluation strategy it uses.
We know how to define the function factorial in a recursive way. Let
us give now an example of mutually recursive functions.
even x=if x=0 then true
else
odd(x-1)
odd x=if x=0 then false
else
even(x-1)
With our recursive definitions we do not only specify functions, but we
also provide a method to compute them: a recursive definition definition says that the left-hand
side part of the equation is equivalent (has the same "meaning")
of the right-hand side. The right-hand side, however, has its meaning expressed
in a more explicit way. We can replace the left-hand side part with the
right-hand one in any expression without modifying its meaning.
We can notice that in order to evaluate "even 3" we can follow
different evaluation strategies. It is also possible to perform more
reductions in parallel, that is to replace two or
more sub-expressions with equivalent sub-expression (reduction step) at the
same time. A similar thing is not possible in imperative languages since we
need to take into account the problem of side effects:
running in parallel the instructions of the subprograms computing two
functions F1 and F2 can produce strange results, since
the two subprograms could use (and modify) the value of global variables
which can affect the results produced by the two functions. Of course,
because of the presence of global variables, the value of a function can
depend on time and on how many times we have computed it before (in general in imperative languages it is difficult to be
sure that we are programming actual mathematical functions.) We have
not the above mentioned problems in functional programming languages, since
there not exists side effects (there are no global modifyable
variables). What we define are therefore actual mathematical functions; hence
in an expression the value of any sub-expression does not depend on the way we
evaluate it or other ones, that is the same expression always denotes the
same value (a property called referential transparency).
1.3 Sketchy introduction to types
Some functional programming languages are typed. A type, in
general, can be looked at as a partial
specification of a program. These partial specifications, according to
the particular type sytem of the language considered, can be more or less
detailed.
By means of types we can avoid errors like:
true + 3
in fact the interpreter knows that
+:: int x int →
int
In (strongly) typed languages this error is detected by the
Type Checker, before the program is "executed". In not (strongly) typed
languages this error is detected at run-time, by the interpreter itself (the program's execution
is stopped whenever an error is detected).
In typed languages not only the functions have a type, but all
the possible correct expressions have (or can be given) a type.
In some typed functional languages it is possible to define polymorphic
functions, that is function which, roughly, have the same behaviour on arguments of
different types (a polymorphic type describes a
whole set of (uniform) behaviours).
Example:
ident:: a → a (a is a
type-variable. It denotes a "generic" type.)
ident x = x
We shall study very simple types, like int->bool (it simply
specifies that a function (program) with this type has an integer as an
argument and a boolean as result). Notice, however, that there exist type
systems so expressive that they can specify in a very precise way what a
function computes. For istance there could be type systems with a type like
Forall x : Int
Exists y: Int . y=x+1
A function with this type
have integers as argument, integers as results, and computes the
successor function (of course the type does not specify how the successor of a given integer is computed).
1.4 Higher order functions and curryfication
In functional programming languages functions are first-class entities, i.e.
can be treated as normal data. Hence they can be given as argument to other functions or
be the result of a function.
A simple example is the following Scheme function
(define High-inc (lambda (x) (lambda (y) (+ x y))))
High-inc takes a number x and returns a functions that increments its argument by x.
The function Inctwo seen before can be seen as the result of applying 2 to High-inc.
As a matter of fact we could have defined Intwo in the following alternative way:
(define Inctwo (High-inc 2))
Function that can have
functions as argument or result are called higher-order functions.
The notion of higher-order function enables us to introduce the notion of curryfication,
a relevant concept in functional languages. To currify means to transform a
function f of arity n, in an higher-order
function fcur of arity 1 such that also fcur(a1) is a higher order function of arity 1, and so are fcur(a1)(a2) up to
fcur(a1)(a2)..(an-1) and such that
f(a1,..,an)=fcur(a1)..(an).
A binary function of type:
A x B →
C
is currifyed to a function of type:
A → (B →
C)
where any function
arity is 1. (Higher-order functions and curryfication are treated in Section
1.7 of the reference below.)
We can notice that the function High-inc is indeed the currified version in Scheme of the
addition.
The possibility of using currified functions definitely improves the expressive power
of functional languages (that is why in Haskell all functions
are already in their currified version,
even the used-defined ones.)
Note:
Also in imperative languages it is possible to program functions which have
functions as arguments, but in general what is given as argument is simply a pointer to
some code (which needs to be treated as such).
1.5 Recursion
The computational power of functional languages is provided by
the recursion mechanism; hence it is natural that in functional languages it
is much easier to work on recursively defined datatypes.
Example:
the datatype
List is recursively defined as follows:
a list is either [] (the empty list) or elem:list (the concatenation of an element with a list).
BinaryTree (unlabelled) is another example:
an element of BinaryTree is either EmptyTree or a root at the top of two elements
of BinaryTree.
Notice that there is a strong relation between the Induction
principle as a mathematical proof tool and Recursion as a computation
tool.
A property is true (for natural numbers) if
- One proves
the base case;
- By assuming the
property to hold for n, one proves the property for n+1
This is the principle of numerical
induction; it closely corresponds to the mechanism of defining a function on numbers
by recursion: A function (on numbers) is defined if
- One defines it for
the base case;
- By assuming the
function to be defined for n, one defines it for n+1
Of course we can use recursion on complex recursive (inductive) data types.
And in fact there exist general versions of the induction principle, as we shall see
in the course.
Data are not modified in (pure) functional programming
We are used to work on data structures that are intrinsically tied to the
notion of "modification", so we usually thing that an element of a
data type can be modified. This is not true in functional programming.
For example, a functional program that takes as input a numeric labelled tree and increments its labels,
does not modify the input. It simply builds a new tree with the needed
characteristics. The same holds when we push or pop elements from a stack: each
time a new stack is generated.
This causes a great waste of memory (the reason
why in implementations of functional programming languages a relevant role is
played by the Garbage Collector). Of course there can be optimizations and
tricks used in implementations that can limit this phenomenon.
Text to use: R. Plasmeijer,
M. van Eekelen, "Functional Programming and Parallel Graph
Rewriting", Addison-Wesley, 1993. Cap. 1 (basic concepts)
2. The λ-calculus and computation theory
2.1 Lambda-terms
The fundamental concepts the Lambda-calculus is based on are:
variable ( formalisable by x, y ,z,…)
abstraction (formalisable
by λx.M where M is a term and x a variable)
application (formalizable
by M N, where M and N are terms
)
We have seen that these are indeed
fundamental notions in functional programming. It seems that there are other
important notions: basic elements, basic operators and the possibility of
giving names to expressions, but we shall see that the three above notions are
the real fundamental ones and that we can found our computational model just on
these three concepts.
Using the formalization of these three concepts we form the lambda-terms.
These terms will represent both programs and data
in our computational model (whose strenght strongly depends on the fact it does
not distinguish between "programs" and "data".)
The formal definition of the terms of the Lambda-calculus
(lambda-terms) is given by the following grammar:
Λ ::= X | (ΛΛ)
| λX.Λ
where
Λ stands for the set of lambda-terms and X is a metavariable that ranges
over the (numerable) set of variables (x, y, v, w, z, x2, x2,...)
Variable and application are well-known concepts, but what
is abstraction ?
In a sense, it is a notion tied to that of "abstracting from a concrete
value" (i.e. disregarding the specific aspects of a particular object, which, in
our case, is an input.)
Abstraction is needed to create anonymous functions (i.e. functions without a name).
When we define in Haskell the function fact,
fact n = if (n=0) then 1 else n*fact(n-1)
we are doing indeed two things: we are specifying a
function and we are giving the name fact to it. Being able to specify a
function is essential in our computational model, but we can avoid to introduce in our model the notion of "giving a
name to a function". You could ask: how is it possible to define a function like fact
without being able to refer to it trought its name??? We shall see.
Example of (functional) abstraction:
We
can specify the square function by saying that it associates 1 to 1*1, 2 to
2*2, 3 to 3*3, ecc. In the specification of the function the actual values of
the possible particular inputs are not needed, that is we can abstract
from the actual values of the input by simply saying that the function square
associates x*x to the generic input x.
We could use the mathematical notation x |—► x*x to specify such a particular relation
between domain and codomain; with such mathematical notation we specify a
function without assigning to it a particular name (i.e. we specify an anonymous function).
In Lambda-calculus we describe the relation input-output by
means of the lambda-abstraction operator: the term λx. M
represents the anonymous function that, given an input x, returns the "value" of the body M.
Other notions, usually considered as primitive, like basic operators
(+, *, -, ...) or
natural numbers, are not strictly needed in our computational model
(indeed we shall see that they can actually be treated
as derived concepts.)
In an abstraction λx.P, the term P is said to be the scope of
the abstraction.
2.2 Free and bound variables
A variable x is said to be bound in M whenever it is abstracted in
some subterm λx.P of M.
A variable is free in M if it is not bound.
These two concepts can be formalized by the following definitions.
Definition of bound variable
We define BV(M), the set of the Bound Variables of M, by induction on the term as follows:
BV(x) = Φ (the emptyset)
BV(PQ) = BV(P) U
BV(Q)
BV(λx.P) = {x} U
BV(P)
Definition of free variable
We define FV(M), the set of the Free Variables of M, by induction on the term as follows:
FV(x) = {x}
FV(PQ) = FV(P) U FV(Q)
FV(λx.P) = FV(P) \ {x}
Free and bound variables represent two different concepts in a term.
A bound variable in the body of an abstraction represents the argument of a function,
whereas a free variable represent an (unknown) value.
2.3 Substitution
The notation M [L / x] denotes the term M in
which any free occurrence of the variable x in M is replaced by the term L.
Definition of substitution (by induction on the structure of the term)
1. If M is a variable (M = y) then:
|
y [L/x] ≡
|
{
|
L if x=y
|
|
y if x≠y
|
2. If M is an application (M = PQ) then:
3. If M is a lambda-abstraction (M = λy.P) then:
|
λy.P
[L/x] ≡
|
{
|
λy.P if x=y
|
|
λy.(P [L /x])
if x≠y
|
Notice that in a lambda abstraction a substitution is performed only if
the variable to be substituted is free (not bound).
The definition of substitution given above, however, is not completely correct.
Indeed it does not prevent
some harmful ambiguities and errors:
Example:
Both terms (λx.z)
and (λy.z)
obviously represent the constant function which returns z for any argument.
Let us assume we wish to apply to both of these terms the substitution [x / z] (we
replace x for the free variable z). If we do not take into account the fact that the variable x
is free in the term x and bound in (λx.z) we
get:
(λx.z) [x / z] =>
λx.(z[x / z]) =>
λx.x representing the identity function
(λy.z) [x / z] =>
λy.(z[x/ z]) =>
λy.x representing the function that returns always x
This is absurd, since both the initial terms are intended to denote the
very same thing (a constant function returning z), but by applying the substitution we
obtain two terms denoting very different things.
Hence a necessary condition in order the substitution M[L/x] be correctly performed is that FV(L) and BV(M) be
disjoint sets.
Example:
Let us
consider the following substitution:
(λz.x) [zw/x]
The free variable z in the term to be substituted would become bound after the
substitution. This is meaningless. So, what it has to be done is to rename
the bound variables in the term on which the substitution is performed, in
order the condition stated above be satisfied:
(λq.x) [zw/x]
now, by performing the substitution,
we correctly get: (λq.zw)
The example above introduces and justifies the
notion of alpha-convertibility
The notion of alpha-convertibility
A bound variable is used to
represent where, in the body of a function, the
argument of the function is used. In order to have a meaningful calculus,
terms which differ just for the names of their bound variables have to be
considered identical. We could introduce
such a notion of identity in a very formal way, by defining the relation of α-convertibility.
Here is an example of two terms in such a relation.
λz.z
=α λx.x
We do not formally define here such a relation. For us it is sufficient to know that
two terms are α-convertible whenever one can be obtained from the other
by simply renaming the bound variables.
Obviously alpha convertibility mantains completely unaltered both the meaning of the
term and how much this meaning is explicit. From now on, we shall implicitely work on λ-terms modulo alpha conversion.
This means that from now on two alpha convertible terms like λz.z and λx.x
are for us the very same term.
Example:
(λz.
((λt. tz) z)) z
All the variables, except the rightmost z, are bound, hence we can rename them (apply
α-conversion). The rightmost z, instead, is free. We cannot
rename it without modifying the meaning of the whole term.
It is clear from the definition that the set of free
variables of a term is invariant by α-conversion, the one of bound
variables obviously not.
2.4 The formalization of the notion of computation
in λ-calculus: The Theory of β-reduction
In a functional language, to compute means to evaluate
expressions. The process of evaluation makes the meaning of a given expression more and more
explicit. Up to now we have formalized in the lambda-calculus
the notions of programs and data (the terms). Let us see now how to formalize
the notion of computation. In particular, the notion of "basic computational step".
In the introduction we noticed that, during the evaluation of a term, whenever there is
a function applied to an argument, this application can be replaced by the body of the
function in which the formal parameter is replaced by the actual argument.
So, if we call redex any term of the form (λx.M)N,
and we call M[N/x] its contractum,
to perform a basic computational step on a term P means that P contains a subterm which is a redex and
that such a redex is replaced by its contractum (β-reduction is applied on the redex.)
Definition (The notion of β-reduction)
The relation between redexes and their contracta is called notion of β-reduction, and it is
formally represented by the following β-rule:
(λx.M) N →β M [N/x]
Definition (One step β-reduction)
We say that a term P β-reduces in one-step to a term Q
(notation: P→βQ) if
Q can be obtained out of P by replacing a subterm of P of the form (λx.M)N by M[N/x]
Example:
If we had the multiplication in our system, we could perform
the following computation steps
(λx.
x*x) 2 => 2*2
=> 4
Here the first step is a β-reduction; the second computation is the
evaluation of the multiplication function. We shall see how this last
computation can indeed be realized by means of a sequence of basic
computational steps (and how also the number 2 and the function
multiplication can be represented by λ-terms).
Example:
(λz.
(zy) z) (x (xt)) →β
(x (xt) y) (x (xt))
Example:
(λy. zy) (xy) →β z(xy)
here it could be misleading the fact that the variable y appears once
free and once bound. As a matter of fact these
two occurrences of y represent two very different things (in fact the bound occurrence of y
can be renamed without changing the meaning of the term, the free one not).
Notice that in this case, even if there is this small ambiguity, the beta
reduction can be performed without changing the name of the bound variables.
Why?
A formal system for the one-step beta-reduction relation
If one wishes to be very precise, it is possible to define
the relation of one-step beta reduction by means of a formal system.
First recall roughly what a formal system is.
Definition
A formal system is composed by axioms and inference rules enabling us to
deduce valid "Judgements"
Example:
In logics we have formal systems
enabling to infer the truth of propositions, that is the judgments we derive
are of the form "P is true".
We can introduce a formal system whose only axiom is the β-rule we have seen
before:
|
———————————
(λx. M) N →β
M [N/x]
|
and whose inference rules are
the following ones:
|
if
then we can infer
|
P →β P'
—————————
λx. P →β
λx. P'
|
P →β P'
—————————
L P →β L
P'
|
P →β P'
—————————
P L →β
P' L
|
The judgements we derive in the formal system defined above have the form M →β M' and are
interpreded as "the term M reduces to the term M' in one step of
computation (β-reduction)".
Example:
in this formal system we can have the
following derivation:
——————
(λx.x)
y → y
——————————
(zz) ((λx.x) y) →
(zz) y
———————————————
λw.((zz) ((λx.x) y)) → λw ((zz) y)
This is a (very formal) way to show that
the term λw.((zz) ((λx.x) y)) reduces in one step to
the term λw.((zz) y) (less formally, and more quickly, we could
have simply spotted the redex (λx.x) y inside the term and
replaced it by its contractum y)
So, our formal system defines a binary relation on lambda-terms, beta reduction,
and we have seen that this can be done informally by saying that a term M is in the relation
→β with a term N (
M β-reduces with one step to
N) if N can be obtained by replacing a subterm of M of the form (λx.P)Q by P[Q/x]
2.5 Bracketing conventions
For readability sake, it is useful to
abbreviate nested abstractions
and applications as follows:
(λx1.(λx2. ... . (λxn.M)
... ) is abbreviated by
(λx1x2 ... xn.M)
( ... ((M1M2)M3) ... Mn)
is abbreviated by (M1M2M3 ... Mn)
We also use the convention of dropping outermost parentheses and those enclosing
the body of an abstraction.
Example:
(λx.(x (λy.(yx))))
can be written as λx.x(λy.yx)
2.6 Curried functions
Let us see what's the use of the
notion of curryfication in the lambda-calculus.
As we mentioned before, if we have,
say, the addition function, is is always possible to use its currified version
AddCurr : N →
(N → N) and any
time we need to use it, say Add(3,5), we can use instead ((AddCurr(3)) 5).
This means that it is not strictly needed to be able to define functions of
more than one argument, but it is enough to be able to define one argument
functions. That is why the λ-calculus, that contains only the strictly
essential notions of functional programming, has only one-argument abstraction.
Notice that, by using
curried functions, not only we lose no
computational power, but, even better,
we get more expressive power. For instance, if we wish to use a
function that increments an argument by 3, instead of defining it we can
simply use AddCurr(3).
Not all the functional
languages have a built-in curryfication feature. Scheme has it not. In Scheme any
function you define has a fixed arity, 1 or more. If you wish to use a
curryfied version of a function you have to define it explicitely. In Haskell
instead, all function are implicitly intended to be currified: when you define
Add x y = x + y you are indeed defining AddCurr.
2.7 Multi-step reduction
Strictly speaking, M → N means that M reduces to N by exactly
one reduction step. Frequently,
we are interested in whether M can be reduced to N by any number of steps.
we write
M —» N
if M → M1 →
M2 → ... → Mk ≡ N
(K ≥ 0)
It means that M reduces to N in zero or more reduction steps.
Example:
((λz.(zy))(λx.x))
—» y
2.8 Normalization and possibility of non termination
Definition
If a term contains no β-redex, it is said to be in
normal form.
Example:
λxy.y and xyz are in normal form.
A
term is said to have a normal form if it can be reduced to a term in normal
form.
Example:
(λx.x)y
is not in normal form, but it has the normal form y
Definition:
A term M is normalizable (has a normal form, is weakly normalizable)
if there exists a term Q in normal form such that
M —» Q
A term M is strongly
normalizable, if there exists no infinite reduction path out of M. That is,
any possible sequence of β-reductions eventually leads to a normal form.
Example:
(λx.y)((λz.z)t)
is a term not in normal form, normalizable and strongly normalizable too.
In fact, the only two possible reduction sequences are:
1. (λx.y)((λz.z) t)
→ y
2. (λx.y)((λz.z) t) →
(λx.y) t)
→ y
To normalize a term means to apply reductions until a normal form
(if any) is reached. Many λ-terms cannot be reduced to normal form. A
term that has no normal form is
(λx.xx)(λx.xx)
This term is usually called Ω.
Although different reduction sequences cannot lead to different normal forms,
they can produce completely differend outcomes: a reduction sequence could lead to
a normal form while onother one could never terminate.
Typically, if M has a normal form and admit also an infinite
reduction sequence, it contains a subterm having no normal form but that can
be erased by some reduction. For instance, the reduction
(λy.a)Ω
→ a
reaches a normal form, by erasing the Ω. This
corresponds to a call-by-name treatment of arguments: the argument
is not reduced, but substituted as it is into the body of the abstraction.
The attempt to normalize the argument, instead, generates an endless reduction
sequence:
(λy.a)Ω
→(λy.a)Ω
→ ...
Evaluating the argument before its substitution into the body of the function correspons to a call-by-value
treatment of function application. In the two examples above,
a call-by-value strategy never reaches the normal form.
One is naturally led to think that the notion
of normal form can be looked at as the abstract formalization in the
lambda-calculus of the notion of value in programming languages.
This, however, is a too naive approach. Even if it is intuitively true that
something that cannot be further evaluated can be considered as a value,
the vice-versa does not hold a-priori.
As a matter of fact there
can be many different interpretations of the notion of value. In Scheme, for
instance, a lambda expression is a value: the interpreter does not
evaluate any expression of the form λy.M.
Why does the interpreter of Scheme choose to consider a
lambda abstraction as a value independently from what there is in its body?
Well, otherwise it would not be possible to define in Scheme, say, a function
that takes an argument and then never stops.
So we cannot formalize in general
the notion of value. What a value is has to be specified according to the
context we are in. So, when we define a functional programming
language we need to specify, among other things, also what we mean by value in
our language.
2.9 Some important results of β-reduction
theory
The normal order reduction
strategy consists in reducing, at each step, the leftmost outermost β-redex. Leftmost means, for istance, to reduce L
(if it is reducible)
before N in a term LN. Outermost means, for
instance, to reduce (λx.M)N before reducing M or N (if
reducible). The Normal Order reduction is obviously a call-by-name evaluation strategy.
Theorem (Standardization)
If a term has a normal form, this is always reached
by applying the normal order reduction strategy.
Theorem (Confluence)
If we have terms M, M2 and M3 such that:
M —» M1 and
M —» M2
then there always exists a term L such that:
M1
—» L and
M2 —»
L
That is, in diagram form:

Corollary (Uniqueness of normal form)
If a term has a normal form, it is unique.
Proof:
Let us suppose to have a generic term M, and let us suppose it has
two normal forms: N and N'. It means that
M —» N and M
—» N'
Let us now apply the Confluence theorem. Then there exists a term Q such that:
N —» Q and N'
—» Q
But N and N' are in normal form and hence they contain no redex. So, it necessarily means that
N —» Q in 0 steps,
and hence that N ≡ Q.
Analogously
we can show that N' ≡ Q.
It is then obvious that N ≡ N'.
Definition
For a binary relation R, the diamond property holds whenever:
if aRb and
aRc, then there exists d such that bRd and cRd
Using the definition above, we can reword
the theorem of confluence in simpler way:
DP(—»)
Note that:
┐DP(→)
The one-step reduction relation does not satisfy the diamond property, that
is, it is not true that the following diagram always commutes

In fact, consider the term (λx.xx)(I
a), where I ≡ λx.x.
In one step this term reduces
to (λx.xx)a or (I
a)(I a). These terms can both be reduced to aa,
but there is no way to complete the diamond with a single-step reduction:

The problem, of course, is that (λx.xx)
replicates its argument, which must then be reduced twice.
Sketck of the Proof of the Theorem of Confluence
2.10 Formalizing the notion of equivalent programs: the
theory of β-conversion
In the actual programming activity we usually talk about
"computational equivalence" of pieces of code or of whole programs
(for instance when we try to do some optimizations.)
Being able to formally deal
with such a notion would be useful for many things, like safely modifying and
optimizing programs or proving properties of programs.
In the present section, we formalize the notion of equivalence of programs into the lambda calculus.
In order to do that we can start by asking ourself what does it means for two terms
to be computationally equivalent.
Informally, we could say that two terms
are so when they "represent the same information".
In such a case the following definition should be the right one.
Definition (The relation of β-conversion)
M is β-convertible to N, in symbols
M =β
N
if and only if M can be transformed into N (or N into
M) by performing zero or more β-reductions and β-expansions.
(A β-expansion
being the inverse of a reduction: P[Q/x] ← (λx.P)Q )
That is, two terms M and N are β-convertible if and only if there exist terms N1,..,Nk (k≥ 0) such that
M —» N1 «— M1—» N2«—
M2 ... Mk-1—»Nk«— M k ≡ N
Let us define now a formal system allowing to derive all, and only, the valid judgements concerning the
beta-convertibility of terms, that is of the form M =βN ("M is β-convertible to N".)
A formal system for β-conversion
Axiom:
|
——————————
(λx.M) N) =β M [N/x]
|
Inference rules:
|
if
then we can infer
|
P =β
P'
—————————
λx. P =β λx. P'
|
P =β
P'
—————————
Q P =β Q P'
|
P =β
P'
—————————
P Q =β P' Q
|
β-conversion is reflexive, symmetric and transitive too, hence we must add also
the following axiom and rules:
|
————
M =β M
|
M =β N
————
N =β M
|
L =β M
M =β N
—————————
L =β N
|
|
|
|
We have thus formally defined the relation of beta-conversion as
the smallest equivalence relation containing the beta-rule and compatible with the
operations of formation of terms (hence a congruence).
We have said before that such a relation aims at being a precise
formalization of the notion of equivalence between (functional)
programs, since, by its definition, it equates terms containing the very same "information".
Are we sure, however, that such "information" we are equating is actually a "computational information"?
In order to answer to such a question, let us notice that we can look at any term as a function
(this is reasonable, since any term can be applied to any other term).
From such a point of view, what does it mean for two terms to represent the
same "computational information"?
Does it just mean that they represent the same function?
i.e. that they "return" the same output when given the same input?
If this were the case,
the notion represented by the relation of β-equivalence
would be useless for us computer scientists,
since we are not only concerned about what output is
produced by a program, given a certain input, but we are also (and mainly) interested
in "how" the result is computed.
In other words, we are more interested in algorithms than in functions
(a computer scientist would not consider a program implementing the bubblesort
equivalent to a program implementing the mergesort, although they both compute the
same function, the sorting one.)
Fortunately the β-conversion relation does not equate two
terms just in case they compute the same function, as can be roughly shown by the following
counterexample. Let us consider the two terms
(λx.yx) and y.
They actually compute the same function from terms to terms since, if we apply the same input,
say M, we get the very same output
1. (λx.yx)M
—» yM
2. yM —»
yM
Nonetheless (λx.yx) and
y are not considered equivalent by the β-conversion relation, since it is
easy to show, using the Church-Rosser theorem below, that
(λx.yx) ≠β
y
So, informally, we can not only say that two β-convertible terms
"contain the same information", but also that this information is actually
a computational, algorithmic information.
It is not wrong then to state that the actual notion formalized by β-conversion is:
two terms
are β-convertible if and only if they compute the same function using
the same algorithm.
For a more convincing example,
when later on we shall represent numerical mathematical function in the lambda-calculus,
you will be able to check that both λnfx.(f(nfx))
and λnfx.(nf(fx))
compute the successor function on natural numbers. Nonetheless, being two
distinct normal forms, they cannot be β-convertible
(by the Church-Rosser theorem). You can notice in fact that they represent
different "algorithms".
And in case we would like to
look at lambda-terms from an extensional point of view? (that is from a mathematical
point of view, looking at them as functions).
Well, in case we were interested in equating terms just when they produce the same output
on the same input,
we should consider a different relation: the beta-eta-conversion.
The theory of beta-eta-conversion (=βη)
The formal system for =βη is like the one for =β,
but it contains an extra axiom:
λx.Mx =η
M if x is not in FV(M)
Instead of adding this axiom, we could, equivalently, add the following inference rule, more intuitive, but with the drawback of having a universally quantified premise:
|
For all L: ML
= NL
——————————
M = N
|
Obviously, from a Computer Science point of view we are more interested in =β
than in =βη
Example: In the theory of beta-eta-conversion it is possible to prove that
(λx.yx) =βη
y
Remark: you could
now wonder why the two non β-convertible terms considered before, λnfx.(f(nfx))
and λnfx.(nf(fx))
cannot be made equal even in the beta-eta-conversion theory. Well, the
lambda-calculus is a very abstract theory and a term has be looked at as a
function on all possible terms, while the two terms above compute the
same function only on a subset of the lambda-calculus terms, that is on those
lambda-terms which represent natural number, the so called Church numerals we
shall discuss shortly.
Let us go back to our
β-conversion and let us have a look at a few relevant
results of the theory of β-conversion.
Theorem (Church-Rosser)
If two terms are beta-convertible (M =β N), then there exists Q such that
M —» Q and N
—» Q
The Church-Rosser theorem enables to prove that the theory of
β-conversion is consistent.
In a logic with negation, we say that a
theory is consistent, if one cannot prove a proposition P and also its
negation ┐P. In general, a theory is consistent if not all judgements
are provable (i.e. there exists some judgments that are not provable).
Thanks to the Church-Rosser theorem, we can show that the
λ-calculus is consistent.
Corollary (Consistency of =β)
There exist at least two terms that are not β-convertible
Proof:
Let us consider the two terms (λx.yx) and y
(any pair of distinct normal forms will work the same).
By contradiction, let us assume that
(λx.yx)
=β y
Then, by the Church-Rosser theorem, there exists a term Q such that
(λx.yx) —» Q and y
—» Q
But since the two terms
are both in normal form, the above reductions must necessarily be 0-step reductions.
This implies that
(λx.yx)
≡ y
This is impossible, hence
(λx.yx)
≠β y
The Church-Rosser theorem and the Confluence theorem are equivalent and in
fact are often used and referred to interchangedly:
The
Church-Rosser theorem (C-R) and the Theorem of confluence (CONF) are logically
equivalent, that is it is possible to prove one using the other
Proof:
C-R =>
CONF
Let us assume the Church-Rosser theorem and prove Confluence.
In order to prove confluence let us take M, M1 and M2 such that
M —» M1 and
M —» M2
By definition of β-conversion we have then that M1 =β
M2. We can now use the Church-Rosser theorem that guarantees that, whenever
M1 =βM2, there exists L such that
M1
—» L and
M2 —»
L
CONF =>
C-R
Let us assume the Confluence theorem and prove the Church-Rosser one.
We then consider two terms M and M' such that
M =β
M'
By definition of beta-conversion, it means that I can transform M into M', by performing zero or more
β-reductions / expansions:
M —» N1 «— M1—» N2«—
M2 ... Mk-1—»Nk«— M k = M'
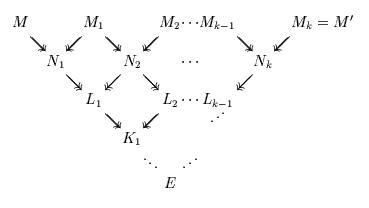
We can now use the Confluence theorem on the
terms M2, N1 and N2, inferring that there exists a term
L1 such that
By iterating the process we get:
We give now an important
theorem of undecidability for the theory of beta conversion.
Definition (Closure by
a relation)
A set S is said to be closed
with respect to a binary relation R iff a belongs to S and aRb implies that b belongs to S
Theorem (Undecidability)
Let A be a
set of lambda-terms which is not trival (that
is, it is not empty and it does not contain all the lambda-terms.)
Then if A is closed by beta-conversion then it
is not recursive (that is, it is not possible in general, given a term, to decide in an effective way whether
it belongs to A or not).
3. Representation of data types and operations in
λ-calculus
3.1 The Natural numbers
In the syntax of the
λ-calculus we have not considered primitive data types (the natural
numbers, the booleans and so on), or primitive operations (addition, multiplication and so on),
because they indeed do not represent really primitive concepts.
As a matter of fact, we can represent them by using the
essential notions already formalized in the λ-calculus, namely variable,
application and abstraction.
The question now is: how can we represent in the λ-calculus a concept like
that of natural number?
We stressed that the λ-calculus is a theory of functions as
algorithms. This means that if we wish to represent natural numbers in the
λ-calculus, we need to look at them as algorithms. How can that be possible????
A number is a datum, not an algorithm! Well... but we could look at a
number as an algorithm. For instance, we could identify a natural number with the
procedure we use to "build" it.
Let us consider the number 2. How can we "build" it?
Well, give me the successor, give me the zero and I
can get the number 2 by iterating twice the successor function on the zero.
How can I represent this procedure? By the lambda-term
λfx. f (fx) !!
Notice that the algorithm to build the number 2 is independent from what the zero and
the constructor actually are. We can abstract from what they actually are
(fortunately, since nobody really knows what zero and what the
successor are. Do you?).
So, in general, we can represent natural numbers as lambda-terms as follows
0 ≡ λfx. x (it represents the natural number 0)
1 ≡ λfx. f x (it represents
the natural number 1)
2 ≡ λfx. f (f
x) (it represents the natural number 2)
3 ≡ λfx. f (f (f
x)) (it represents the natural number 3)
.......................................................................................
n ≡ λfx. f nx
(it represents the natural number n)
where we define f nx as
follows: f 0x = x ;
f k+1x = f(f kx)
n denotes the lambda-representation of the
number n.
The above encoding of the natural numbers is the original one developed by
Church. The terms just defined are called Church's numerals. Church's encoding
is just one among the many ones that it is possible to devise.
The technique to think of data as algorithms can be
extended to all the (inductively defined) data.
Example:
I can represent an unlabelled binary tree by
the function that takes two inputs (the empty tree and the constructor that adds a
root on top of two binary trees) and that returns as output the expression that represents how
to build the desired tree out of the emptytree and the constructor.
In order to be sure that the
representation of natural numbers we have given is a reasonable one, we have to
show that it is also possible to represent in the lambda-calculus the
operations on numbers. But what does it mean for a function on natural
numbers to be definable in the lambda-calculus?
Definition (λ-definability)
A function f: N → N
is said to be λ-definible (representable in the λ-calculus) iff there exists a
λ-term F such that, for all n:
F n =β
f(n)
The term F is said to represent the function f.
Example:
To represent the function factorial, we need to find a λ-term (let
us call it fact) such that, whenever applied to the Church's numeral
that represents the natural number n, we get a term that is
β-convertible to the Church's numeral
representing the factorial of n, that is
fact 3
=β 6
Why have we not defined how to represent in
the lambda-calculus the numerical
functions with more that one argument? Well, since it is enough to be able to
represent their curryfied versions. So the definition given is enough.
We shall see shortly how to define binary numerical functions like addition.
What we shall do is to look at addition as AddCurr : N →
(N → N)
Before seeing how to lambda-represent some numerical functions, let us see how
we can represent the Booleans.
3.2 The Booleans
An encoding of the booleans corresponds to defining the terms true,
false and if, satisfying (for all M and N):
if true M N = M
if false M N = N
The following encoding is
usually adopted:
true ≡ λxy.x
false ≡ λxy.y
if ≡ λpxy.pxy
As exercise, check that if actually works.
We have true ≠ false by the
Church-Rosser theorem, since true and false are distinct normal
forms. All the usual operations on truth values can be defined using the
conditional operator. Here are negation, conjunction and disjunction:
and ≡
λpq. if p q false
or ≡ λpq. if p true
q
not ≡ λp. if p false true
3.3 Arithmetic on Church's numerals
Using Church's encoding of natural numbers, addition,
multiplication and exponentiation can be defined very easily as follows:
add ≡ λmnfx.mf (nfx)
mult ≡ λmnfx.m (nf) x
expt ≡ λmnfx.nmfx
Addition is not hard to
check. In fact:
|
add m
n
|
≡
|
(λmnfx.mf (nfx)) m n →β (λnfx.
m f (nfx)) n →β
|
|
|
→β
|
λfx. m f (n
f x) ≡ λfx.(λgx.gm x) f ((λhx.hn
x) fx) →β
|
|
|
→β
|
λfx.(λgx.gm x) f ((λx. f
n x) x) →β
λfx.(λgx.gm x) f (f n x) →β
|
|
|
→β
|
λfx.(λx.f m x)(f n x) →β λfx.fm
(f n x) ≡ λfx.f m+n x ≡
|
|
|
≡
|
m+n
|
Multiplication is slightly more difficult:
|
mult m
n
|
≡
|
(λmnfx.m(nf) x) m n →β (λnfx.
m (nf) x) n →β
|
|
|
→β
|
λfx. m (n
f) x ≡ λfx.(λgx.gm x) (n f)
x→β →β
|
|
|
→β
|
λfx.(n f)m x → λfx.((λhx.hn
x) f)m x →β
λfx.(f n)m x ≡ λfx.f mx n x ≡
|
|
|
≡
|
m x n
|
These reductions hold for all Church's numerals m and n,.
Here are other simple definitions:
succ ≡
λnfx. f (nfx)
iszero ≡ λn.n (λx. false) true
The following reductions, as you can check by yourself, hold for any Church's numeral n:
succ n —» n+1
iszero 0 —» true
iszero (n+1) —»
false
Of course it is also possible to define
the predecessor function (pred) in the lambda calculus, but we do not
do that here.
Example:
We can easily give the representation of
the following mathematical function on natural numbers
|
f(n,m)=
|
{
|
3+(m*5) if n=0
|
|
(n+(3*m)) otherwise
|
by means of the following lambda-term:
λnm. if (iszero n) (add 3 (mult m 5)) (add
n (mult 3 m))
3.4 Defining recursive functions using fixed points
In the syntax of the λ-calculus there is no
primitive oparation that enables us to give names to lambda terms. However, that of
giving names to expressions seems to be an essential features of
programming languages in order to define functions by recursion, like in Scheme
(define fact (lambda (x) (if (= x
0) 1 (* x (fact (- x 1))))))
or in Haskell
fact 0 = 1
fact n = n * fact (n-1)
Then, in order to define recursive functions, it would seem essential to be
able to give names to expressions, so that we can recursively refer to them.
Surprisingly enough, however, that's not true at all!
In fact, we can define recursive functions in the lambda-calculus by using
the few ingredients we have already at hand, exploiting the concept of
fixed point.
Definition
Given a function f: A → A , a fixed point of f is an element a of A such that
f (a)
= a.
In the lambda-calculus, since we can look at any term M as a function from lambda-terms
to lambda-terms,
i.e. M : Λ →
Λ, we can define a fixed point of M, if any, to be any term Q such that:
M Q =β
Q
To see how we can fruitfully exploit the concept of fixed point, let us consider an
example. Let us take the definition of factorial using a generic sintax
factorial x = if
(x=0) then 1 else x * factorial(x-1)
The above
equation can be considered a definition because it identifies a precise
function. In fact the function factorial is the only mathematical function which satisfies
the following equation, where f can be looked at as an "unknown" function
f x = if x=0
then 1 else x * f(x-1)
The above
equation can be rewritten as follows, by using the lambda notation
f =λx.
if x=0 then 1 else x * f(x-1)
The function we are defining is hence a fixpoint,
the fixpoint of the functional
λf.λx.
if x=0 then 1 else x * f(x-1)
In fact it can be checked that
(λf.λx.
if x=0 then 1 else x * f(x-1)) factorial = factorial
Now, we want to lambda-represent the factorial
function. It is easy to see that the functional
λf.λx.
if x=0 then 1 else x * f(x-1)
can be easily lambda-represented:
λ
f.λx.if (iszero x)
1 (mult (f(sub x 1)) x)
Then, a lambda term F that lambda-represents the
factorial function must be a fixed point of the above term. Such an F would in
fact satisfy the following equation
F x =β if (iszero x)
1 (mult x (F(sub x 1)))
and hence would be really the lambda-representation of the factorial.
But is it possible to find
fixed points of lambda-terms? And for which lambda-terms? Well, the following
theorem settles the question once and for all, by showing us that indeed all lambda-terms
have a fixed point. Moreover, in the proof of the theorem, it will be shown how
easy it is possible to find a fixed point for a lambda term.
Theorem
Any λ-term has at least one fixed point.
Proof.
We prove the theorem by showing that there exist lambda terms (called fixed
point operators) which,
given an arbitrary lambda term, produce a fixed point of its.
One of those operators (combinators) is the combinator Y
discovered by Haskell B. Curry.
It is defined as follows:
Y ≡
λf. (λx. f(xx)) (λx. f(xx))
It is easy to prove that Y is a fixed point combinator.
Let F be an arbitrary λ-term. We have that
|
Y F
|
≡
|
(λf. (λx.
f(xx)) (λx. f(xx))) F →
(λx. F(xx)) (λx. F(xx)) →
|
|
|
|
→
|
F ((λx. F(xx))
(λx. F(xx))) ←
|
(3)
|
|
|
←
|
F((λf.(λx. f(xx)) (λx. f(xx)))F) ≡ F (Y F)
|
|
That is
F (Y F) =β
(Y F)
Then the λ-term that represents the factorial function
is:
Y(λf.λx.if (iszero x)
1 (mult x (f(sub x 1))))
Let us consider another example of recursively defined function.
g x = if (x=2) then 2
else g x
(*)
What is the function defined by
this equation? Well, it is the function that satisfies the equation,
where g is considered an "unknown" function.
Ok, but we have a problem here, since it
is possible to show that
there are many functions that satisfy this equation. In fact, it is easy to
check that
factorial x
= if (x=2) then 2 else factorial x
And also the identity
function satisfies the equation, since
identity x =
if (x=2) then 2 else identity x
And many more. For instance, let us consider
the function gee
that returns 2 when x=2 and that is undefined otherwise. Well, also gee satisfies
the equation:
gee x = if
(x=2) then 2 else gee x
So, which one among all the
possible solutions of (*), that is which one among all the possible fixed point of
the functorial
λg.λx. if x=2 then 2 else g x
do we have to consider as
the function identified by the definition (*)?.
We all know that it is gee the intended function
defined by (*). Why?
Because implicitely, when we give a definition like (*), we are
considering a computational process that identifies the least among
all the possible solutions of the equation (least in the sense of
"the least defined"). This means that, in order to correctly
lambda-define the function identified by an equation like (*), we cannot consider
any fixed point, but the least fixed point (the one that corresponds to the
least defined function that satisfies the equation.)
The question now is: does the Y combinator picks the right fixed point?
If a lambda term has more than one fixed point, which is the one picked up
by Y?
Well, fortunately Y behaves really well. It not only returns a fixed point of a
term, but the least fixed point, where, informally, by "least" we mean the
one containing only the information strictly needed in order to satisfy
the equation. Of course we could formalize in a precise mathematical sense what is the meaning,
for a term, to have "less information" than another one, and hence what is the precise
meaning of being a least fixed-point. But such a formalization would go beyond the scope of these
introductory course notes.
It is enough for us to know
that the least fixed point of the functional
|
λf. λx.
if iszero (pred (pred x)) 2 (f x)
|
|
and hence the lambda term
lambda-representing the function gee is
Y(λf. λx.
if iszero (pred (pred x)) 2 (f x))
Let us look at some other examples
Example:
Let us consider the λ-term
λx.x
It is immediate to check that any term M is a fixed point of λx.x (the
identity function) because
(λx.x)M
=β M
The least fixed point of
λx.x is Ω, since
Y
(λx.x) = Ω
It is reasonable that Ω be the least among all the lambda-terms
(any lambda-term is a fixed point of the identity)
since this term is intuitively the one "containing" the least information (actually no information at all).
Example:
Let us consider the function that diverges on any element of its domain. It can be
defined by the following recursive equation:
h x = h x
The λ-term that represents the function h is the solution of the
equation
h = λx.
h x
that is, the least fixed point of
λf.
λx. f x
The
least fixed point of this term is hence the lambda-representation of the function that diverges everywhere.
Let us go back now to the Figure (3), where Y F is proved to be beta convertible
to F(Y F) by means of two β-reductions followed by
one β-expansion. Notice that it is impossible to have
Y F —» F (Y F)
If we wish to have such a behaviour we have to look for a different fixed point combinator,
for instance Alan Turing's Θ, which is defined in the following way:
A ≡ λxy.y (xxy)
Θ ≡ AA
Its peculiarity is that we
have that
Θ F —» F (Θ F)
The Why of
Y.
We now show, in an intuitive way, why the
combinator Y (and the fixed point combinators in general) works.
Let us consider
once again the equation that defines the factorial function
(and that at the same time provides a way to compute it.)
factorial x = if (x=0) then 1 else x * factorial(x-1)
From this equation we can obviously get
factorial x = if (x=0) then 1 else x * ( if (x-1=0) then 1 else
(x-1) * factorial(x-1-1) )
and also
factorial x = if (x=0) then 1 else x * (if (x-1=0) then 1 else
(x-1) * (if (x-1-1=0) then 1 else (x-1-1) * factorial(x-1-1-1) )
)
and so on....
To compute the factorial, in a sense, we unwind
its definition as many times as it is needed by the argument, that is until
x-1-1-1...-1 gets equal to 0. Such an unwinding is exactly what the Y combinator
does. In fact
Y F =β
F(Y F) =β F(F(Y F)) =β
F(F(F(Y F))) =β F(F(F(F(Y F))))
=β ... and so on
If you take as F the lambda-term
λf.λx.if (iszero x)
1 (mult x (f (sub x 1)))
, by applying a beta-reduction you get
Y F =β λx.if (iszero x)
1 (mult x ((Y F)(sub x 1)))
but you can also get
Y F =β λx.if (iszero x)
1 (mult x ((if (iszero (sub
x 1))
1 (mult (sub x 1) ((Y F)(sub (sub
x 1) 1)))
and so on and so on...
That is (Y F) is
beta-convertible to all the possible "unwindings" of the factorial definition.
Then if you apply 2 to
(Y F) you can
get, by a few beta-reduction
(Y F)2 =β if (iszero
2)
1 (mult 2 ((if (iszero (sub 2 1))
1 (mult (sub 2 1) (if (iszero (sub (sub
x 1) 1))
1 (mult (sub (sub x 1) 1) ((Y F)(sub (sub (sub
x 1) 1) 1)))))
We can
easily check that the term on the right is beta convertible to
2, that is to the factorial of 2.
So, why does
Y work? Because, in a sense, it is an "unwinder", an "unroller" of definitions.
Using Y (and hence recursion) to define infinite objects.
We have seen before how to represent a few simple data types in the lambda-calculus and
we have said that it is easy to devise a representation for all the inductively defined
data types. In particular, it is possible to represent the data type List with its basic
element emptylist and the list constructor cons that we shall use below
without giving their explicit definition.
Let us consider the following λ-term:
Y (λl. cons x l)
(*)
It is definitely a fixed point.
It is the fixed point of the term λl. cons x l. If we give a list ls
as input to this term, it returns a new list formed by x followed by ls.
It is not difficult to check that the least fixed point of λl. cons x l
is the infinite list of x's. This
means that the term Y (λl. cons x l) represents an
infinite object!
So, in the lambda-calculus Y can be used not only to represent
recursively defined functions, but also recursively defined object. In fact
we could define the infinite list of x's by means of the following equation:
Infinite = cons x Infinite
Of course we cannot
completely evaluate Y (λl. cons x l)
(i.e. get all the information it contains),
since the value of this term would be an infinitely long term (and in fact
it does not have a normal form).
But nontheless we can partially evaluate it in order to get finite
approximations of the infinite list of x's.
You see, after a few beta reductions and beta conversions we can
obtain
Y F =β (cons x (cons
x ( cons x (Y F)))) where F is the term (*)
and this term is a finite approximation of the
infinite list of x's. Of course the term (*) is convertible to all the
possible finite approximations of the infinite list of x's. This means that it is possible to use and work with terms
representing infinite object. In fact, it is easy to check that
car (Y
(λl. cons x l)) =β
x (**)
where car is the λ-representation of the
function that, taken a list, returns its first element. So
it is possible to use the term (*), even if it represents an
infinite object (it is reasonable to be able to pick the first element from an
infinite list.)
What we have seen here shows that in functional programming it is
possible to deal also with infinite objects. Such a possibility, however, is not
present in all functional languages, since when we evaluate an expression in a
functional language we follow a precise reduction strategy, and not all the reduction
strategies enable us to safely handle infinite objects.
In Scheme it is not possible since, in a term like (**) above,
Scheme would keep on endlessly evaluating the argument of car.
In Haskell, instead, the evaluation of a term like (**) terminates.
In order to better understand this fact, see the section below on evaluation strategies.
3.5 Reduction strategies
One of the aspects that
characterizes a functional programming language is the reduction strategy
it uses. Informally a reduction strategy is a "policy" which chooses a
β-redex , if any, among all the possible
ones present in the term. Abstractly, we can look at a strategy as a function.
Definition
A reduction strategy is a function
S: Λ → Λ
(where Λ is the set of all the λ-terms), such that:
if S(M) = N then M →β N
Let us see, now, same classes of strategies.
Call-by-value strategies
These are all the strategies that never reduce a redex when the
argument is not a value.
Of course we need to precisely
formalize what we intend for "value".
In the following example we consider a value to be a lambda term in normal
form.
Example:
Let us suppose to have:
((λx.x)((λy.y)
z)) ((λx.x)((λy.y) z))
A call-by-value strategy never reduce the
term (λx.x)((λy.y) z)
because the argument is not a value. In a call-by-value strategy , then, we
can reduce only one of the redex underlined.
Scheme uses a specific
call-by-value strategy, and a particular notion of value.
Informally, up to now we have considered as "values" the terms in
normal form. For Scheme, instead, also a function is considered to be a value
(an expression like λx.M, in Scheme, is a value).
Then, if we have
(λx.x)
(λz.(λx.x) x)
The reduction strategy of Scheme first reduces the biggest redex (the whole term),
since the argument is considered to be a value (a function is a value for Scheme).
After the reduction the interpreter stops, since the term λz.((λx.x) x) is a value for Scheme and hence cannot be further evaluated.
Call-by-name strategies
These are all the strategies that reduce a redex without checking whether its
argument is a value or not. One of its subclasses is the set of lazy
strategies. Generally, in programming languages a strategy is lazy if it is
call-by-name and reduces a redex only if it's strictly necessary to get the
final value (this strategy is called call-by-need too). One possible
call-by-name strategy is the leftmost-outermost one: it takes, in the set of
the possible redex, the leftmost and outermost one.
Example:
Let us denote by I the identity function and let us consider
the term:
(I (II))
( I (II))
the
leftmost-outermost strategy first reduces the underlined redex.
We have seen before that the leftmost-outermost strategy is very
important since, by the Standardization Theorem, if a term has a normal form,
we get it by following such a strategy. The problem is that the number of reduction steps
is sometimes greater then the strictly necessary ones.
If a language uses a call-by-value strategy, we have to be careful because if
an expression has not normal form, the search could go on endlessly.
A fixed point combinator for Scheme-like strategies
Let us consider the functional F that has the factorial function
as fixed point. Then we have that
(Θ F) 3
—» 6
Let us suppose to use a call-by-value strategy like that of Scheme. We get
(Θ F) 3
→ (F (Θ F)) 3
→ (F (F (Θ F))) 3
→ ...
If we would like to use the
above fixed point operator to define recursive function in Scheme (we do not
do that when we program in Scheme, of course), we have this problem.
We could overcome this problem, however, by defining a new fixed point
combinator, H, that, if we wished, we could safely define
and use in Scheme as well (do it as an exercise when you study Scheme).
Let us consider the following λ-term:
H ≡ λg.((λf.ff)
(λf.(gλx.ffx)))
It's easy to prove that this term is a fixed point operator. In fact we have
that:
(H F)
—» F (λx. AAx)
where A is (λf.F λx.ffx) and
(HF) —» AA. From the
point of view of the computations, we can write it in this form:
(H F)
—» F (λx. H
Fx)
Functionally, F (λx. H Fx) has the same behaviour of HF,
but Scheme does not reduce it because that is a value for Scheme. Then if, for
example, F is the functional whose fixed-point represents the function factorial,
if we wish to
compute the factorial of 5 we can evaluate the term ((HF)5).That
is we have to evaluate
(F (λx. H
Fx)) 5
and this evaluation is possible withouth getting into any
infinite reduction sequence. If you compute the factorial of 5 in Scheme in this way,
you will have to wait a bit of time in order to get the result...
3.6 Head Normal
Forms
In the previous sections, we have
implicitly assumed that in λ-calculus, if a term has not a normal form,
then it represents no information at all. For example:
Ω has
not normal form and it represents the indefinite value
But this is not always true, that is it is possible to have terms that have
no normal form but nonetheless represent ("contain") some information.
We have already seen an example of this fact: the λ-term
Y (λl. cons x l)
(*)
which It has no normal form, but it represents a precise
object that contains an infinite amount of information. We cannot get such information all
together (it would be an infinitely long term), but we have seen before that we
can get all possible finite approximations of the information it contains.
So, it is definitely possible to use and work with
terms that have no normal form but nonetheless posses
a "meaning".
Note:
As discussed in the section about infinite objects, we have to be careful
about the strategy we intend to use when manipulating expressions without normal form.
If we tried to evaluate an expression like car(( Y (λl. cons x l))
and we used a call-by-value strategy with terms without normal form as values,
we would get stuck in a loop, since we would try to get a value
out of Y (λl. cons x l).
In a language like Haskell, instead,
we would obtain x (When you begin to have a look at Haskell, read also the
notes [HASK] on laziness and infinite objects, available in the reading
material)
How is it possible to
formalize in the lambda-calculus the notion we have informally discussed above? That is, the notion of a term containing some
information even if it has no normal form.
We do that by means of the definition of head normal form,
the formalization of the notion of finite approximation of the meaning of a term.
Definition
A term is in head normal form (hnf) if, and only if, it has a form as follows:
λx1...xk.yM1...Mn (n,k≥ 0)
where y can be any variable, also one of the xi's.
If a term in head normal form λx1...xk.yM1...Mn had a normal form, the normal form would have the following shape:
λx1...xk.yN1...Nn
where N1,...,Nn would be the
normal forms of M1,...,Mn.
If the term, instead, had no normal form, it is easy to check that in any case the portion of the term
λx1...xk.y
will stay always the same after any possible sequence of reduction steps.
(Note that a term in normal form is also in head normal form).
Example:
Let us consider the term:
λxyz.z(λx.x)(λzt.t(zz))(λt.t(λ (λxx)))
it is in
normal form, but it is in head normal form too.
Let us consider, now, Ω.
It is not in head normal form and it has no head normal form.
Now, going back to the notion of term containing no information (term
representing the indeterminate), we have just seen that some information can
be obtained out of terms having no normal form. So when can we say that
a
term really contains no information at all? Well, now we can answer: when a
term has no head normal form!
Are we sure this to be the right answer? Well, the following fact confirms
that it is really the right answer:
Let us take two terms not having head normal form, for example:
Ω
and Ωx
Using the Church-Rosser theorem we can prove they are not β-convertible. Now
If we add to the β-conversion theory the axiom:
Ω = β Ωx
the theory of beta-conversion does remain
consistent. It is no surprise, since this axiom is stating that a term that
contains no information
is equivalent to a term that contains no information, no contradiction in
that!
Then, we can rightly represent the indeterminate with any term that has not head normal form.
Infact we could consistently add to the theory of the beta-conversion the
axiom stating that all the terms with no head normal form are β-convertible
(this intuitively means that we could consistently make "collapse" all the possible
representations of the indeterminate into one single element).
4. Types
4.1 Introduction to types
The functional programming languages can be typed or untyped.
A typed one is, for example, Haskell, while an untyped language is Scheme. By introducing
the notion of type in the λ-calculus we shall be able to study it in an abstract
and simplified way.
We can look at types as predicates on programs or, better, as partial specifications
about the behaviour of programs. In the programming practice the use of types
is helpful to prevent a number of programming errors.
There are two different approaches to the use of
types.
- the approach a'
la Curry (the one used in Haskell)
- the approach a'
la Church (the one used in Pascal)
In the Curry approach, we first write a program and then
check whether it satisfies a given specification.
Instead, in the Church approach, types are included in the syntax of the
language and, in a sense, represent some constraints we have to follow during
the writing of our programs in order to avoid making particular errors.
In the approach a' la Curry, checking if a term M satisfies the specification
represented by the type t, it is usually
referred to as "assigning the type t to the term M".
4.2 Type assignment 'a la Curry
In this approach we firsr write a
program and then we check whether it satisfies the specification we had
in mind. This means that we have two distinct
sets: programs and partial specifications.
If we wish to talk in a general and abstract way about types (a' la Curry) in
functional programming languages we can proceed with the following
formalization:
|
Programs :
the set of λ-terms, i.e.
|
/
|
Partial
specifications: the set of types, i.e.
|
|
Λ
|
T ::=
φ | T → T
|
where φ is a meta-variable which ranges
over a set of type variables (φ, φ', φ'', a, b, ... etc.).
In this formalization we have considered the simplest
form of type (in fact these types are called simple types).
Elements of T will be denoted by σ, τ , ρ, etc.
There arise now a whole bunch of
questions we should answer:
1) How can
we formally show that, given a program (a term) M and a specification (a type) σ,
M satisfies the specification σ? That is, how can we prove that M has type σ?
2) Is it decidable, given a M and a σ, that M
is of type σ? i.e., given a program (term) M and a specification (type) σ,
is there any algorithm enabling us to check whether M satisfies σ?
3) Do types play any role during a computation?
4) What is the intrinsic meaning of having type variables in our system? has the use of type variables some implication for our system?
5) Is it possible to "compare" types? i.e.,
is it possible to formalize the notion that a type represents a "more general" specification
than another one?
6) Is there any relation among all the possible types
we can assign to a term M? there exists the most general type among them? If so, can it be
algorithmically found?
Let us start with question 1).
What we need to do is to devise a formal system whose judgments (typing judgements) are of
the form
M : σ
and whose meaning is: the program M respects the specification σ
(formally, the term M has type σ).
If we think about it, however, we can notice that our typing judgments should provide some more
information than simply M : σ.
In fact, let us consider the term λx.yx. Which sort of specification is satisfied by
such a program?
In case the input is of type φ, a type for λx.yx is definitely
of the form
φ →
something
But now, how can we found out what something could be, if we do not have any
information about the free variable y? Our program (term) takes an input x and returns
the result of the application of y to x. If we do not make any assumption about the
type of the free variable y, we cannot say anything about the type of yx.
This means that the (typing) judgments we are looking for should indeed have the
following shape:
B |— M:σ
where B (called a basis), provides informations about
the types of the free variables of M.
The meaning of the typing judgment B |—
M : σ is then:
using the informations given by the basis B, the term M satisfies the specification
σ
(i.e. M has type σ under the assumptions provided by the basis B; or,
shortly, M has type σ in B.)
Formally B will be a set of pairs of the form :
variable : type
An example of basis is, for instance,
B = {x : τ , z : ρ}
Let us introduce now the formal system enabling us to infer
types for lambda-terms.
Definition (Curry type assignment system)
Axiom
|
—————
B |— x : σ
|
if x :
σ is in B
|
(a variable x has type σ if the statement x :
σ is in B).
Inference rules
These rules allow to derive all the possible valid
typing judgements.
|
B |—
M : σ → τ
|
B |— N : σ
|
|
———————————————
B |— MN : τ
|
This rule says that if, by using the assumptions in B, we can prove that M
has type
σ → τ and N has type σ, then we are assured that,
in the basis B, the application MN has type τ.
This rule is usually called (→E): "arrow elimination".
This rule can be "read" also bottom-up, as follows: if we wish to prove that MN has type
τ in B, then we need to prove that M has type σ → τ
in B for some σ and that N has type σ in B.-
|
B, x : σ |— M : τ
—————————
B |— λx.M : σ →
τ
|
This rule says that if, by using the assumptions in B and the further
assumption
"x has type σ", we can prove that M has type τ, then we
we are assured that, in B, λx.M has type
σ → τ. This rule is called (→I)
: "arrow introduction". Also this rule can be
"read" bottom-up. Do it as exercise.
A term M is called typeable if there exist a basis B and a type σ
such that the judgment
B |— M : σ can
be derived in the assignment system above.
The above formal system is the core of the
type systems of languages like Haskell, ML and others. This is the main
motivation for which we are studying it.
Remark:
In Haskell, before writing the definition of a
function, we can declare what type our function is intended to have, for instance:
fact :: Int →
Int
By doing that, after defining the function
fact the Haskell
interpreter can check whether our program fact satisfies the given specification.
In particular, the interpreter tries to derive, in a formal system like the one defined before,
the Haskell typing judgement fact :: Int →Int.
Note: In Haskell we have not the concept of basis, because in
correct programs an identifier either is a bound variable or it has been previously associated
to some value.
Example:
Let Ø be the empty set and let us
consider the judgment
Ø |— λxy.x : σ →
(τ → σ)
whose informal meaning is: by considering no assumption
at all (the empty basis), the term
λxy.x satisfies the specification σ → (τ → σ).
If we wish to formally prove that the above judgment is valid, we need to
use the Curry type assignment system.
Let us start from the axiom:
|
————————
{x : σ, y : τ} |— x :
σ
|
By using (→I) two times, we get
|
{x : σ, y :
τ} |— x : σ
————————
{x : σ} |— λy.x
: τ → σ
———————————
Ø |— λx.λy.x
: σ → (τ → σ)
|
Let us notice that in the last two steps we have discharged, from the basis
we have started with, the assumptions for the bound variables of the term.
In fact, a basis has to provide only informations about free variables,
since the informations about bound variables are already contained in the type of the term.
Example:
We want to prove that:
B = {f : σ →
σ, x : σ} |— f (f (fx))
: σ
Starting from B, we use the axiom and the rules of our formal system:
|
——————
B |— f : σ → σ
|
————
B |— x : σ
|
|
|
|
————————————
B |— (fx) : σ
|
——————
B |— f : σ → σ
|
|
|
———————————————————
B |— f (fx) : σ
|
——————
B |— f : σ → σ
|
|
————————————————————————————————
B |— f (f (fx)) : σ
|
We can go on and derive, from the derivation above, other judgments:
|
{f : σ →
σ, x : σ} |— f (f
(fx)) : σ
—————————————
{f : σ → σ} |—
λx.f (f (fx)) : σ → σ
———————————————
Ø |— λf.λx.f
(f (fx)) : (σ → σ) → (σ → σ)
|
Remark:
There are programs that do not satisfy any
specification, whatever be the basis B. For example, let us consider:
B |— xx : τ
It is impossible to derive this judgment in our system, whatever basis B and type τ we choose.
What is the implication of this simple observation? Well, typed
languages restrict the set of programs we can write, but on the other hand the programs we can
write are safer, i.e. they are guaranteed not to contain certain errors and to satisfy their
partial specifications. We loose something of course, that is flexibility,
the possibility of writing "tricky" and "sly" programs.
So, in typed languages: less flexibility = more safeness.
There is a quite relevant property of typeable terms that concerns strong normalizability.
Theorem
Any typeable term is strongly normalizable.
So, since self-application cannot be typed, it follows that
the combinator Y cannot be typed. This implies that we cannot type any term
representing a recursive algorithm. This is also why, whereas in Scheme, if we wished, we
could define recursive programs using fixed-point combinators, in Haskell it is not possible.
Of course this is not a real drawback for Haskell, since it is not realistic to write
actual recursive programs by means of fixed-point combinators.
In Haskell recursion is obtained by the use of recursive equations (which corresponds to
the possibility of giving names to expressions.)
Let us now discuss another relevant property of our type assignment system: Subject
reduction
Saying that M has type σ (M : σ ) amounts to
say that M represents a value of type σ. The types do not give information about the form of the terms (about their syntax), but, instead, they provide informations about
their intrinsic meaning, their semantics.
Hence, if a term has a certain type, it is important to be sure that
during its evaluation the term "maintains"
the same type.
For example, if a term M represents a program that returns a number, types
would be useless if we could reduce
M to a term that represents a program which returns a list.
Fortunately we can prove the following
Theorem (Subject reduction)
If in a basis B we can prove that M has type σ, that is
B |— M : σ
and if M —» N, then we
can also prove that
B |— N : σ
Thanks to this theorem we are sure that, if we check that a term M has a given type at the
beginning of a computation, then we can forget about types during the
computation, since all the terms that we obtain by reducing M
can be given the very same type.
This also implies that types are irrelevant, do not
play any role, in the computational process.
Let us note that the subject reduction property holds only for
reductions and not for expansions. That is, if we have that
B |— N : σ and
M —» N
it is not always true that
B |— M : σ
By means of the Subject
reduction theorem we have also answered question 3).
Let us now try and answer question 4). Question 2) has still to
be answered, but it will be done using the answer for 6)
Definition (Type substitution)
Let T be the set of simple types:
a) the type substitution (φ  ρ) : T → T,
where φ is a type-variable and ρ is a type, is inductively defined by:
ρ) : T → T,
where φ is a type-variable and ρ is a type, is inductively defined by:
(φ ρ) φ = ρ
(φ ρ)
φ' = φ', if φ' ≠ φ
(φ ρ) σ
→ τ = ((φ ρ) σ) → ((φ ρ) τ)
The above definition formalizes the
notion of "substituting a type variable by a type inside a type"
b) We can
compose type substitution, that is, if S1,
S2 are type substitutions, then so is S1oS2,
where:
S1oS2 σ = S1
(S2 σ)
c) A
type substitution can also be applied to a basis: SB = {x : Sτ | x : τ is in B}
d) A type substitution can also be applied to pairs of
basis and type (it will be useful later on)
S <B, σ> = <SB, Sσ>
Note:
The notion of substitution for types is much simpler than the one for terms,
since in simple types we do not have bound type-variables.
Example: if we
apply the type substitution (φ
σ) to the type φ → (τ→ φ), and if τ does not contain φ,
we obtain the type σ →
(τ→ σ)
If for σ,τ there is a substitution S such that Sσ = τ,
we say that τ is a (substitution) instance of σ.
The following lemma shows that if a term has a type,
it has indeed infinitely many tipes. The Lemma will provide, at the same time, an answer
to question 4).
Lemma (substitution lemma)
If using a basis B we can prove that a term M has a type σ, that is
B |— M : σ
then, for all possible substitutions S, we can also prove that:
S(B) |— M : S(σ)
So the Substitution Lemma states that if a term satisfies a specification, then it satisfies infinitely many ones (because we can have infinitely many possible substitutions.)
Example:
It is easy to prove that
{x : φ →
ψ} |— λy .xy :
φ → ψ
The Substitution Lemma states that if we apply any substitution S,
it is also true that
S({x : φ →
ψ}) |— λy .xy :
S(φ → ψ)
For example, by considering the substitution
(φ
(φ' → φ)) o (ψ
ξ)
it is true that
x : (φ' →
φ) → ξ |— (λy
.xy) : (φ' → φ) → ξ
Example:
If we have derived
Ø |— λx.x : φ →
φ
by the Substitution Lemma we are sure that also the
following judgment is derivable
Ø |— λx.x : (ψ →
φ) → (ψ → φ)
What we have just seen means
that in our formal system we have polymorphic functions (a function is
called polymorphic if it can be correctly applied to objects of
different types).
So, by using type variables, we have implicitly introduced a notion of polymorphism in our
type assignment system.
Since this system is the core of the type system of Haskell, this implies that
Haskell is a language with polimorphism. (In Haskell type variables have names
like a, b, c etc.)
To state that the lambda term λx.x has type a → a
is tantamount to say that λx.x is a polymorphic function, that is it can be uniformly
applied to any element of any type T and it returns an element of type T.
The type a → a is (implicitly) a polymorphic type since, being "a" a type-variable,
it "represents" all the types with shape T → T.
The polymorphism of our system can be said to be implicit,
since the fact that a term has many types it is not explicitly expressed in the
syntax by means of particular operators on types,
but it is expressed by results like the Substitution Lemma.
A possible syntax for explicit polymorphism could be the following one:
λx.x :
for all φ.φ → φ
In this case the polymorphic behaviour of the term is explicitely described
by the sintax.
We can now provide, using the notion of type substitution, an answer to question 5)
by giving the following definition.
Definition (more general type)
Let τ and σ be two simple types.
τ is said to be more general than σ
if there exists a substitution S such that σ = S(τ).
That is if the latter can be obtained from the former by means of a type substitution.
We know that if a term M has a type, it has infinitely many ones. Now, it is also
possible to prove that there exists a precise relation among all the types that a given
term has (i.e. all the possible partial specifications of a program are, so to speak,
connected to each other).
That would be an answer for question 6). Such an answer
will also provide an answer for question 2) that up to now we have left unanswered.
4.3 Principal pairs
Theorem
Given a term M, if M is typeable then it has a Principal Pair
<P, π>, where P is a basis and π a type such
that:
1) we can derive the following typing for M
P |— M : π
2) Moreover, if we can derive
B |— M : σ
then there exists a substitution S such that B = S(P) (as a matter of fact B could be a superset of S(P)) and σ =
S(π).
In other words, the principal pair represents the most generic
typing possible for M. That is, any other basis and type that we can use to type M can
be obtained from the principal pair.
This partially answer our question 6)
Example:
Let us consider the term:
λx.x
It has principal pair:
<Ø, φ →
φ>
This means that any other typing for the
identity is a substitution instance of
this principal pair.
The proof of the principal pair algorithm can be given by providing an algorithm that, given a term M, returns
its principal pair, pp(M), and fails in case M be
not typeable.
These completes the answer of our question 6).
Before giving the formal description of the Principal Pair Algorithm, let us first
informally describe how it works.
The algorithm tries to type the given term in the most general way (that is to find the
most general basis and the most general type for the term.)
It tries to do that by using the rules of the assignment system, in a bottom-up way.
If we consider a variable x, well, the only way to type it is by using an axiom,
and the most general axiom for x is definitely the one that has only x in the basis
and a type-variable as type for it.
If we consider an abstraction λx.M
we know that the only way to type it is by using rule (→I).
It is then clear that if we wish to type λx.M in the most general way
by means of this rule, we first need to find the most general typing for M (by using recursively
the algorithm itself. If we fail the whole algorithm fails). Once we have the most general typing for M, if x is in the basis
(with a certain type, say σ) then the most general type for λx.M will be
σ → π (where π is the most general type found for M).
Otherwise, if x is not in the basis (that is, x is not a free variable of M) the
most general typing for λx.M is φ → π, where π
is the most general type found for M and φ is a type variable not yet used (if x is
not a free variable of M it means that the input of λx.M could be anything
and hence a type-variable φ is the most general type for such a generic input.
If we consider an application (MN)
we know that the only way to type it is by using rule (→E).
It is then clear that if we wish to type MN in the most general way
by means of this rule, we first need to find the most general typing for M and the
most general typing for N (by using recursively the algorithm itself.
If we fail the whole algorithm fails).
Once we have the most general basis and type for M, say P1 and π1,
and the most general basis and type for N, say P2 and π2,
these bases and types, however, cannot be used to type MN with the rule (→E)
unless π1 is an arrow type having π2 as domain. If this
is not the case, we can profit from the Substitution Lemma and find the simplest
substitution that, when applied to π1 and to (π2 → φ),
makes them equal (φ is a new type variable).
Once we have such a substitution, say S1 (we find it by means of another algorithm called unify.
If it fails the whole algorithm fails), we apply it to P1, π1,
P2 and π2. Unfortunately, we cannot use rule
(→E) yet, since the bases used in the two premises of the rule
must be the same, and in general it is not true that S1 P1 is the same as
S1 P2.
This means that we need to find another substitution S2 (the simplest
one), by means of which we manage to make S1 P1 and S1 P2 equal (in their common variables). If we manage to find such a substitution (otherwise the whole algorithm fails)
we are done, since now we can use rule (→E) to type MN with S2 S1 φ
from the basis
S2 S1 (P1UP2) (we consider the union
because the free variables of M could be different from the free variables of N).
The formalization of the process we have informally presented before is therefore the
following recursive algorithm.
Definition (The principal pair algorithm)
Given a term M we can compute its principal pair pp(M), if any, as follows:
a) For all x, φ : pp(x) = < {x : φ},φ>
b) If pp(M) = <P, π> then:
i) in case x is in FV(M)
(and hence there is a σ such that x : σ is in P) we define
pp(λx.M)
= <P\x , σ → π>
ii) otherwise, in case x is not a free variable, we define
pp(λx.M) = <P, φ →
π>, where φ does not occur in <P, π>.
c) If pp(M1) = <P1, π1>
and pp(M2) = <P2, π2> (we choose,
if necessary, trivial variants such that the <P1, π1>
and <P2, π2>
contain distinct type variables), φ is a type-variable that does not occur in any
of the pairs <Pi, πi>, and:
S1 = unify π1
(π2 → φ)
S2 = UnifyBases(S1 P1) (S1
P2)
then we define
pp(M1M2) = S2oS1<P1UP2,
φ>. (unify and UnifyBases are defined below)
Of course, we should also prove that this algorithm is correct and complete,
but this would go beyond our scopes.
The principal pair algorithm provides also an answer to
question 2). In fact,
if a term is not typeable the algorithm fails, whereas it returns its principal
pair if it is typeable. So, if a term is typeable we can not only effectively
find it out,
but, in a sense, we can have all its possible types, since any possible typing
can be got out of the principal pair.
Extensions of the above algorithm are used in languages like Haskell and ML.
Let us roughly see how it is used: let us define a function,
say
Id x = x
And let us write now the following thing (that amounts to asking to the Haskell interpreter the following
question: "what is the principal type of Id?")
:type Id
What the interpreter does is to run an algorithm similar to the one we have defined above,
producing the principal type
of the term associated to the identifier Id (the principal type and not the
principal pair, since our Haskell expressions must be closed).
In case of Id the interpreter returns
a → a
Onother possibility in Haskell is instead to "declare" the type of an expression
before we write it, for instance:
Id : (Int →
b) → (Int → b)
After the type declaration we can write the "code" for Id, that is
Id x = x
Now, what the interpreter does is the following: it finds the principal type of the expression
associated to Id and then checks whether the specification we gave, (Int →
b)→ (Int → b), can be obtained out of the principal type of Id by
means of a type substitution.
You can notice that the pp algorithm uses the unify and UnifyBases
sub-algorithms (described below). The unify algorithms takes two types and
checks whether there exists a substitution that makes them equal. That is why
sometimes the Haskell interpreter gives you a warning saying that it does not
manage to unify some type variable, say a. This means that the unify algorithm
implemented in the interpreter does not manage to find a substitution
enabling the unify algorithm to successfully terminate.
Definition (Unify and UnifyBases)
Let B the collection of all bases, S be the set
of all substitutions, and Ids be the substitution that replaces
all type-variables by themselves.
i) Robinson's unification algorithm . Unification of Curry types is
defined by:
unify :: T x T → S
unify φ τ = (φ
τ), if φ does not occur in τ
unify σ φ = unify φ σ
unify (σ → τ) (ρ → μ) = S2oS1,
where S1 = unify σ ρ and S2 = unify
(S1 τ) (S1 μ)
ii) By defining the operation UnifyBases, the
operation unify can be generalized to bases:
UnifyBases ::
B x B → S
UnifyBases B0, x:σ B1, x:τ
= S2oS1
UnifyBases B0, x:σ B1 = UnifyBases
B0 B1, if x does not occur in B1.
UnifyBases Ø B1 = Ids.
where S1 = unify σ τ and S2 = UnifyBases
(S1 B0) (S1 B1)
Notice that unify
can fail only in the second alternative, when φ occurs in μ.
4.4 The typed lambda calculus a' la Church.
We have seen that in the Curry approach to types there is a neat
separation between terms and types. The underlying "programming
philosophy" being that we first write untyped programs and after that we
use the type inference system either to check (possibly under certain
assumptions -the basis-) if the program is typeble with a given
type or to find its principal type (by means of the the pp algorithm).
In the Church approach, instead, the types get involved during the
construction of the term (program) itself.
In a sense, types are part of the program and are
used as "constraints" preventing the programmer to make certain mistakes.
A fundamental property of the Church approach is that each term has just one single type.
This is achieved by imposing every variable to have (to be declared
to have) just one type. The constraint of declaring the type
of each variable is adopted in several programming languages, like
C, C++, Java, Pascal, lambda Prolog,
Since in the typed lambda calculus a' la Church each term has just one type, the set of
terms is partitioned in subsets, one for each type.
The set of types is defined as follows.
T :: INT | BOOL | T → T
Of course we might choose to have even more base types, not just INT and BOOL.
Notice that, unlike in the Curry system, we have no type variable.
In the Curry system, if a term M has a type containing type
variables, say a → a, then M has infinitely many
types (by the Substitution Lemma), whereas in the Church system
a term has just one type. This is also the motivation why, if we wish to
introduce the notion of polymorphism in a Church system, it has necessarily to be explicit polymorphism.
Let us introduce now the rules of our system. Unlike in the Curry
system, they are not type inference rules, but rather term formation
rules, in which types sort of "guide" the correct formation of terms.
For any possible type we assume there exists an infinite set of variables having
that particular type. We assume also that there exist no two
variables with the same name but with different types.
The type of a variable will be denoted by means of
superscripts, like in xt (the variable with name x and type
t.)
We shall denote by Λt the set of well-formed typed lambda terms having
type t.
Definition (Well-formed typed lambda terms)
The (term formation) rules of the typed lambda calculus a' la Church defining the sets Λt,
are the following ones:
For each typed variable xt, xt belongs to
Λt;
If M belongs to Λt1→t2 and N to Λt1, then
(MN) belongs to Λt2;
If M belongs to Λt2, then λxt1.M belongs to Λt1→t2;
Notice that in the last clause, in case x is a free variable of M, it has necessarily the type t1
of the abstracted variable, since variables with the same name do have the same type.
Property (Uniqueness of type)
Let M belongs to Λt1 and to Λt2, then t1=t2.
It is possible to develop also for the typed lambda calculus a' la Church a theory of beta-reduction and a theory of beta-conversion, starting, respectively, from the following axioms
(λxt1.M)N →β M[N/xt1]
(λxt1.M)N =β M[N/xt1]
and proceeding in a similar way as in the untyped lambda-calculus.
In the above axioms, (λxt1.M)N has obviously to be a well-formed term.
It can be proved that M[N/xt1] is well formed if (λxt1.M)N is so
and that they have both the same type (belong to the same Λt).
In the Church typed lambda-calculus, the following questions naturally arise:
- given a term, is it well-formed? that is, has it been formed correctly using the rules
of the system?
- given a well formed term, what is its type?
The answers to these questions are provided by the Type Checking algorithm (TC).
Such algorithm, given a term, checks whether it has been correctly formed and,
in case, returns its type.
Definition (Type Checking algorithm)
TC(xt) = t if xt belongs to Λt; fails otherwise
TC(MN) = t2 if TC(M) = t1 → t2 and TC(N) = t1; fails otherwise
TC(λxt1.M) = t1 → t2, is TC(M) = t2 and xt1
belongs to Λt1; fails otherwise.
We say that a term M type checks if the TC algorithm does not fail on M.
It is easy to see that TC(M)= t iff M belongs to Λt
As can be expected, it is possible to prove the "Church version" of the subject reduction
property.
Theorem (Type preservation under reduction)
If M belongs to Λt and M —»
N, then N belongs to Λt
Similarly to the Curry system, the following relevant theorem holds:
Theorem (Strong Normalization)
Let M be a well-formed typed term in the Church system, then M is strongly normalizable.
4.5 Relation between the systems of Curry and Church
As can be expected, there exists a strong relation between the two type systems described
in the previous sections.
Given a simply-typed lambda term M, let |M| denote the untyped lambda term obtained from M by removing the type decorations.
Then we have that if M type checks, then |M| is Curry-typeable.
Viceversa, if a lambda term N is Curry-typeable, then we can find a suitable type for the bound variables of N, so to obtain a term in the Church system. More precisely, if we add base types to the types of the Curry system, the following holds:
Proposition
(i) If M is a well formed term in the Church system and TC(M)=A, then |M| can be given the type A in the Curry system (from a suitable basis). Note that the viceversa does not hold. Also note that A is not necessarily the principal type of |M|.
(ii) If N can be given a type A in Curry, then there exists a well-formed Church typed term M such that TC(M)=A and |M| = N.
4.6 Lambda-calculus extensions and their type systems a' la Curry.
We have said that the type system a' la Curry we have introduced in the previous sections
is essentially the one used by the language Haskell. However, if we wish to investigate
in an abstract way functional languages like Haskell, we cannot use just the pure
lambda-calculus terms to represent programs.
In fact, we know that lambda-terms typeable in the type system a' la Curry are strongly
normalizable, whereas not all typeable Haskell terms are so.
We cannot type fixed point operators like Y and this prevents using the notion
of recursion in the simply typed lambda-calculus a' la Curry.
In Haskell, instead, we have recursion (since we have the possibility of giving names to
terms).
Hence, if we wish to study the properties of languages like Haskell in a still general
and abstract framework, a possibility is to extend the lambda-calculus in order to
make is a bit closer to a real language, for what concerns both terms and types.
Let us call LC+ our extended calculus.
We assume LC+ to contain constants. For instance constants for numbers
(once we know that we can represent numbers in the pure lambda-calculus, we can use
constants instead, for sake of readability and computational efficiency):
0, 1, 2,
ecc., constants for booleans: true, false,
constants for numeric functions like add, mul,
ecc.
and also a constant for the conditional expression: if.
If we wish we can introduce a constant for the pair constructor:
[-], and many more, if we wish.
(For semplicity's sake we shall denote by [M,N]
the term [-]MN). If we have the pair constructor we also need the
two selectors on pairs:
first and second.
Notice the difference between having a constant for a certain value, say true,
and having that value represented by a term, λxy.x (we have called it
true just in order to better handle it in our expressions.)
As discussed before, since we wish to have a typed calculus and we wish to deal with
recursion, we need to introduce the notion of recursion explicitely, by means
of a recursor operator constant: fix.
The set of terms of LC+ can be defined almost as the set of terms of the
pure lambda-calculus. The terms are build using abstraction and application starting
from variables and constants.
Adding constants to our calculus, however, it is not enough.
If, from now on, you ask your friends to call you "Carlo Rubbia", is this enough
to make you a great scientist? Of course not. It is not the name "Carlo Rubbia"
that makes a person a great scientist. It is how the person "behaves".
A cat is a cat not beacuse you call it "cat", but because it catches mice.
So, it is not enough to extend the lambda-calculus with a constant add
in order to have the operation of addition in LC+. We need to introduce in
LC+ something that makes add behave like the addition operation.
So, we add new axioms in the reduction theory of LC+, besides
the one of beta-reductions. Axioms that specify the computational "behaviour" of constants,
axioms like
add 1 2 -->add
3
add 4 5 -->add
8
etc. etc.
And all those that are necessary for the constants we have, like
if true M N -->if
M
if false M N -->if N
first [M,N] --> [-]
M
etc. etc.
Of course we have not to forget the axiom describing the computational behavior
of fix:
fix F -->fix F(fix
F)
We can now take into account the type system a' la Curry for LC+.
Since we have constants for numbers, booleans, etc., we need also to have base types like
INT, BOOL, etc.
Of course in our system we have arrow types, but since we have introduced pairs, we
need to have also product types. That is, if T1 and T2, also
T1xT2 is a type.
Now, in order to have a reasonable type system, we cannot allow constants to have
arbitrary types. When we use our formal system to infer a type for a term
it would be unreasonable to assume that 3 has type φ → BOOL.
So, what we need to do is to prevent constants to appear in a basis B and to
extend our type inference system with new axioms, like
———————
B |— 3 : INT
and
—————————————
B |— add : INT→INT→INT
for any possible basis B.
And so on.
Notice that in the axiom for if we need to specify that it can be
polymorphically typed:
—————————————
B |— if : BOOL→Sφ→Sφ→Sφ
for any possible basis B and substitution S.
For what concerns the fix operator, its typing axiom is obviously
———————————
B |— fix : (Sφ→Sφ)→Sφ
for any possible basis B and substitution S.
To deal with product types we need to add an inference rule:
B |— M : σ B |— N : τ
———————————————
B |— [M,N] : σxτ
Of course the property of strong normalization for typeable term does not hold anymore in LC+.
We can now use LC+ and its typing system to describe particular notions
of programming languages like Haskell and to study their properties.
For instance we can formally define the lazy reduction strategy of Haskell
by means of the following formal systems for typeable terms of LC+.
The Lazy reduction strategy
Axioms
———————
M -->lazy N
If M -> N is a reduction axioms, that is the one of beta-reduction or one for the operator constants, for instance if true M
N -->if M.
Rules
M -->lazy M'
---------------------------
add M N -->lazy add M' N
M -->lazy M'
---------------------------
add n M -->lazy add n M'
if n is a numeric constant
M -->lazy M'
---------------------------
Eq? M N -->lazy Eq? M' N
M -->lazy M'
---------------------------
Eq? n M -->lazy Eq? n M'
if n is a numeric constant
M -->lazy M'
------------------------------------
if M N P -->lazy if M' N P
M -->lazy M'
---------------------------
first M -->lazy first M'
M -->lazy M'
---------------------------
second M -->lazy second M'
M -->lazy M'
---------------------------
MN -->lazy M'N
Notice that the lazy reduction strategy does not reduce neither inside an abstraction
nor inside a pair.
Of course it is possible to define extended version of the lambda-calculus also
with type systems a' la Church (the system PCF is a well known example of typed
extended lambda-calculus a' la Church).