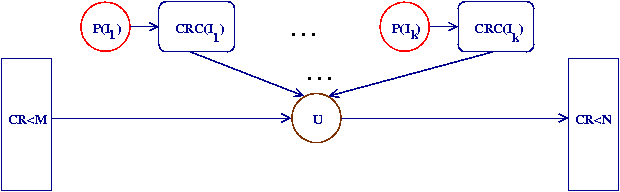
such laws may speed-up
delay computation, yet CR finding does need exhaustive search
this is easily parallelized by partitioning the search space into disjoint
intervals, explored by independent jobs,
each producing its own set of CR candidates
smallests members, in the given interval, of each delay class
the final merge of distributed search results thus amounts to select
the best,
i.e. smallest, candidate for each delay class
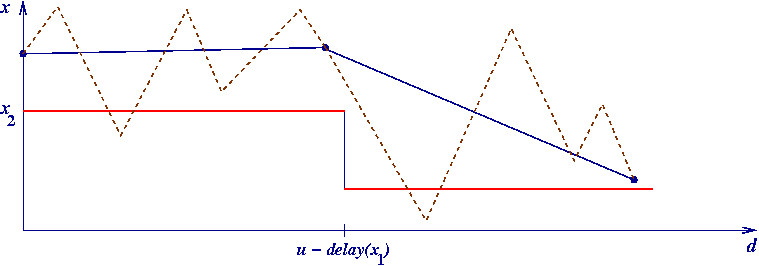
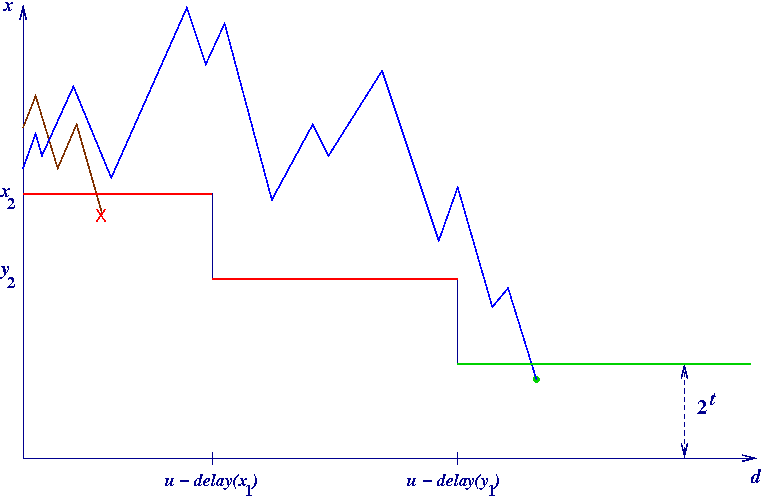
all trajectories leading to 1 (veritably all, thus) sooner or later
fall below 2t,
for any given, fixed t
delay computation may thus get quicker by storing all delay(n)
for n < 2t,
and then adding delay(n) to the partially computed delay of x as soon as the
trajectory starting at x reaches such an n
how to choose the tail cut-off threshold parameter
t ?
by similar, architecture-dependent data as for the sieve size:
available RAM size ?
a surely lower threshold proves optimal
(t between 12 and 16, usually),
that depends on
a small acceleration of delay computation comes from replacing
the function f with
T,
defined as f on the even numbers, whereas
for oddx
one has
Tx = (3x + 1)/2 = x + ⌈x/2⌉
clearly, if the T-trajectory from
x to 1 has
D applications of this rule and
E applications of the halving rule, then
delay(x) = 2D + E
the interest in T comes from the existence
of a permutation of the residues (mod 2k),
defined by the k-prefix of the so-called
parity vector of
T-trajectories,
viz. the binary sequence, dependent on x,
defined by
vi(x)
= (T ix) mod 2
the k-prefix of
vi(x)
only depends on
x (mod 2k)
thus one may define 2k distinct
k-step composites of T, and decide which applies to x by only looking at
x (mod 2k): not so small acceleration, by clever programming techniques
approximate average CPU time h (in hours)
to search an interval of size 244,
in the neighbourhood of 256:
uh
1925
160
1951
150
1964
148
1985
124
remark:
the latest performance gain is also due to the introduction of a
new pair of consecutive DRs, which has nearly doubled the highest
Head cut-off threshold