MIC-2
ANIMATOR
Fusione del ciclo di esecuzione dell'interprete con il microcodice
Unità per il fetch delle istruzioni
Prima di passare alla descrizione della struttura dell'applet e del suo funzionamento, penso sia utile dare qualche breve informazione di carattere teorico che possa aiutare a capire un po' meglio l'architettura del MIC-2. Preciso che questa breve introduzione non può essere tanto esauriente da soddisfare i diversi aspetti teorici e concettuali dell'argomento; pertanto la trattazione sotto scritta è rivolta a quanti abbiano già appreso le conoscenze di base riguardo l'architettura del MIC-1 e del MIC-2.
La produzione che segue è stata realizzata esclusivamente a scopo didattico per favorire altri studenti che come me si sono imbattuti nello studio del MIC-2. Ricordo inoltre che quest'applet non è un vero e proprio simulatore dove l'utente può eseguire tutti i programmi IJVM che vuole, ma solo un esempio di come un vero simulatore si comporterebbe se fosse capace di eseguire programmi IJVM dettati dall'utente. Lo scopo però è quello di far capire come funziona il MIC-2 e non quello di realizzare un emulatore MIC-2.
Per avere maggiori informazioni sull'applet o per comunicarmi eventuali errori, nuovi consigli per migliorare aspetti grafici e quant'altro, contattatemi al mio indirizzo e-mail: gregoryz@inwind.it, oppure contattate il prof. F. Barbanera all'indirizzo: barba@dipmat.unict.it.
Il MIC-1, come sappiamo, non è il massimo dell'efficienza; con opportuni accorgimenti e l'aggiunta di un po' di hardware è possibile migliorarne le prestazioni. Per incrementare la velocità di esecuzione vi sono tre approcci:
1. Ridurre il n. di cicli di clock necessari all'esecuzione di un'istruzione
2. Semplificare l'esecuzione in modo che il ciclo di clock sia più breve.
3. Sovrapporre l'esecuzione delle istruzioni.
Il MIC-2 implementa alcuni aspetti di questa sintesi.
Esamineremo alcuni modi per ridurre il n. di microistruzioni per ogni istruzione ISA, ovvero riducendo il path-length.
Fusione del ciclo di esecuzione dell'interprete con il microcodice
Nel MIC-1 il ciclo principale consiste di una microistruzione (Main1 PC=PC+1;fetch) che deve essere eseguita all'inizio di ogni istruzione IJVM. In alcuni casi tale microistruzione si può sovrapporre all'istruzione precedente. Consideriamo ogni sequenza di microistruzioni che termina con un salto verso Main1. La microistruzione del ciclo principale si può attaccare alla fine della sequenza (anziché all'inizio) con un salto a più direzioni che è replicato in molti punti. In alcuni casi la microistruzione Main1 può fondersi con le microistruzioni precedenti (se questi ad esempio contengono un ciclo di attesa).
Esempio:
POP nel MIC-1 Nuovo POP (migliorato).
pop1 MAR=SP=SP-1;rd pop1 MAR=SP=SP-1;rd
pop2 (attesa) pop2 PC=PC+1;fetch
pop3 TOS=MDR; goto Main1 pop3 TOS=MDR;goto(MBR)
pop4 PC=PC+1;fetch;goto(MBR)
Nel MIC-2, la sequenza dell'istruzione pop è stata ridotta a tre avvantaggiandosi del ciclo di clock quando l'ALU non veniva usata in pop2. Notiamo che la fine di questa sequenza salta direttamente al codice specifico per l'istruzione ISA seguente.
Ecco quindi la prima tecnica per ridurre la lunghezza del path: Includere il ciclo dell'interprete al termine di ogni sequenza di microcodice.
Proviamo ad inserire un bus in più di input per l'ALU; quasi tutti i registri dovrebbero avere accesso ai 2 bus di input. Il vantaggio di avere un bus in più sta nel fatto che diventa possibile sommare qualsiasi registro a qualsiasi altro registro in un solo ciclo.
Esempio:
ILOAD nel MIC-1 ILOAD nel MIC-2
iload1 H=LV iload1 MAR=LV+MBRU;rd
iload2 MBRU+H iload2 MAR=SP=SP+1
iload3 MAR=SP=SP+1 iload3 TOS=MDR;wr;goto(MBR1)
iload4 PC=PC+1;fetch;wr
iload5 TOS=MDR; goto Main1
Main1 PC=PC+1;fetch;wr
Qui vediamo che LV viene copiato in H solo per renderne possibile la somma con MBRU in iload2; con il nuovo progetto a 3 bus si salta un ciclo poiché diventa possibile somare LV con MBRU direttamente. Tenendo conto anche del punto precedente le microistruzioni di iload passano da 5 a 3, con un notevole guadagno sulle prestazioni temporali.
Ecco la seconda tecnica per ridurre la lunghezza del datapath: Passare da un datapath a 2 bus ad un datapath a 3 bus
Unità per il fetch delle istruzioni
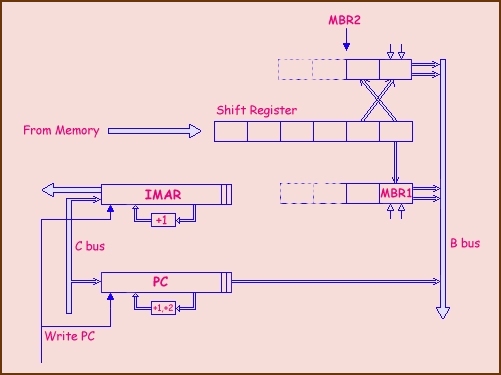
In MIC-1 si può rimuovere gran parte del carico dell'ALU creando un unità indipendente per il fetch delle istruzioni. Questa unità, chiamata IFU (Instruction Fetch Unit) può incrementare il PC in modo indipendente e leggere byte dalla method area prima che siano necessari. IFU è inoltre in grado di assemblare gli operandi da 8 e da 16 bit in modo che siano immediatamente disponibili al momento giusto. IFU interpreta ogni opcode determinando quanti campi supplementari vanno letti e li assembla in un registro pronto all'uso da parte dell'unità principale di esecuzione. l'IFU può avvantaggiarsi del fatto che le istruzioni sono organizzati in sequenza e far si che i successivi 8 e 16 bit siano sempre disponibili. In figura viene mostrato l'IFU; notiamo che invece di un solo MBR adesso abbiamo MBR1 di 8bit e MBR2 di 16bit. L'IFU ha 2 interfacce con il bus B: MBR1 ed MBR1U; il primo è signed-extended ed il secondo è zero-extended. MBR2 ha le stesse caratteristiche di MBR1, ma fornisce i due byte seguenti. L'IFU è responsabile per la lettura del flusso di byte dalla method area che viene effettuata usando una porta della memoria convenzionale di 4 byte, leggendo parole intere di 4 byte prima del necessario e caricando byte consecutivi nel registro di SHIFT che le fornisce uno o due alla volta nell'ordine in cui sono state lette. La funzione del registro di SHIFT è di mantenere una coda di byte dalla memoria per alimentare MBR1 e MBR2.
Fig. 1 - Schema sintetico dell' Instruction Fetch Unit (I.F.U.)
Quando viene letto MBR1, il registro di SHIFT viene spostato avanti di 1 Byte, quando viene letto MBR2 viene spostato di 2 Byte. Poi MBR1 e MBR2 vengono ricaricati rispettivamente dal byte più vecchio e dalla coppia di byte più vecchi, come mostrato in fig. Se c'è spazio sufficiente per un'altra word intera nel reg. di SHIFT allora l'IFU inizia un ciclo di memoria per leggerla. Assumiamo che quando viene letto uno dei registri MBR, questo verrà ricaricato di nuovo all'avvio del ciclo seguente. La dinamica dell'IFU segue la logica del seguente FSM (Finite State Machine):
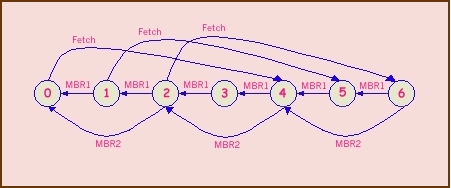
Fig. 2 - Automa a stati finito (FSM) che regolamenta l' I.F.U.
Transizioni:
'MBR1' succede quando MBR1 viene letto; 'MBR2' succede quando MBR2 viene letto; 'Fetch' succede quando è stata letta una parola e 4 Byte vengono messi nel registro di Shift.
L'IFU ha un suo registro per indirizzare la memoria chiamato IMAR e viene usato quando si deve leggere una nuova parola. Questo registro ha il suo incrementatore dedicato. L'IFU deve controllare il bus C in modo che quando viene caricato il PC, anche il nuovo valore venga copiato in IMAR. Quando ciò accade IFU fa partire un segnale di lettura all'indirizzo posto in IMAR e lo SHIFT viene sovrascritto con i nuovi dati aggiornati. L'unità principale di esecuzione scrive sul PC solo quando si deve cambiare la sequenza di esecuzione (tipicamente quando c'è un'istruzione di salto). L'IFU deve anche "sentire" quando è stato letto MBR1 o MBR2 e aggiornare il PC di conseguenza sommando rispettivamente 1 o 2 al suo valore grazie ad un incrementatore separato. Il PC contiene sempre l'indirizzo del primo byte non consumato. Osserviamo inoltre che PC indirizza Byte e il suo incrementatore conta Byte, IMAR indirizza word e il suo incrementatore conta word.
La terza tecnica per ridurre la lunghezza del path di esecuzione è: Leggere le istruzioni dalla memoria per mezzo di un'unità funzionale specializzata.
Alcune informazioni di carattere generale
E' importante capire che: i dati per arrivare dalla memoria ad un registro specializzato impiegano un ciclo di clock intero; il registro MPC viene caricato alla fine del ciclo (ovvero sul fronte di salita del clock); il registro MIR viene caricato all'inizio del ciclo (ovvero sul fronte di discesa del clock); il registro IMAR dell'IFU punta sempre alla word successiva a quella già presente nel registro di SHIFT.
Per quanto riguarda l'utilizzo dell'applet è molto semplice. Per caricare un programma IJVM di esempio in memoria premere il bottone Load Exaple 1 o 2. I programmi IJVM possono essere visionati cliccando sui bottoni a fianco a quelli di caricamento. A questo punto la memoria viene riempita dai dati del programma scelto e i registro di SHIFT memorizza la prima word dell'esempio. In MBR1 abbiamo l'offset del primo opcode appena eseguito. Per computare, come abbiamo già detto, abbiamo 2 possibili scelte. Si possono eseguire le microistruzioni in un ciclo di clock intero e vedere i risultati prodotti nei registri, oppure suddividere l'esecuzione della microistruzione in 4 sottocicli virtuali premendo il bottone Clock-subCycle, in questo modo sarà possibile anche vedere l'animazione delle varie parti del datapath. L'istruzione appena eseguita si trova nel registro MIR, mentre al 4° ciclo di clock è possibile osservare il cambiamento del registro MPC che verrà fatto puntare alla successiva microistruzione da eseguire (che è vista in NEXT_MicroInstruction). L'utente è informato sullo stato della macchina dalla piccola area di testo posta in fondo all'applet, così quando l'esempio sarà terminato l'utente verrà informato di questo evento. E' possibile riportare indietro la macchina di uno stato alla volta premendo il testo Prev.microstep. L'IFU è possibile scoprirlo o nasconderlo tramite l'apposito bottone posto nel pannello in alto a sinistra. La memoria ci appare come una frame attivabile tramite l'apposito tasto. Le Info relative si trovano al di sotto, sempre nello stesso pannello. Il Control Store, infine, si trova tra i registri MIR e NEXT e il pannello di controllo in alto appena sotto il CLOK Panel, esso si può scorrere e osservare da cima a fondo e inoltre accorgersi della microistruzione prossima sotto esame grazie alla barra evidenziatrice.
Auguro a voi tutti, BUONO STUDIO.