| Prev | Top | Next |
Macchine Intermedie e Struttura a livelli dei computer moderni
La differenza di potenza espressiva fra una macchina astratta che vogliamo realizzare
e la macchina che abbiamo a disposizione per tale realizzazione (Macchina Ospite
o HOST) è detta semantic gap.
Spesso il semantic gap tra la macchina da realizzare e
la macchina HOST è talmente grande che è opportuno introdurre
una o piu' macchine astratte intermedie.
Tipicamente, nell'implementare un linguaggio di programmazione (cioe' la sua
corrispondente macchina astratta)
non si procede mai per pura compilazione o pura interpretazione
su una data macchina HOST.
La pura interpretazione potrebbe non essere soddisfacente a causa della scarsa
efficienza della macchina realizzata emulando via software strutture dati, algoritmi e soprattutto l'interprete.
Anche una realizzazione puramente compliativa a causa di un notevole semantic gap
potrebbe portare a produrre programmi per la macchina ospite di dimensioni
eccessive e magari lenti, senza considerare le difficolta' che si possono incontrare
per sviluppare dei traduttori tra linguaggi eccessivamente diversi.
Uno schema implementativo molto usato prevede una fase compilativa seguita da interpretazione;
la situazione è rappresentata nella figura seguente:
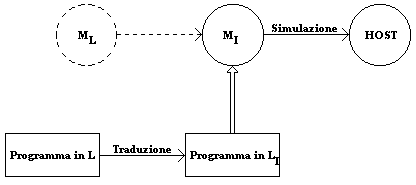 |
Per colmare il divario fra la macchina ML e la macchina HOST, si progetta
un'apposita macchina intermedia MI che viene realizzata sulla macchina HOST.
A questo punto la traduzione dei programmi in L avverrà in termini
del linguaggio di MI, e successivamente il programma per MI
cosí ottenuto verrà eseguito tramite interpretazione sulla macchina HOST.
Nel progetto della macchina intermedia bisogna tenere conto di due
requisiti di efficenza:
- velocità di simulazione della Macchina Intermedia MI sulla macchina HOST;
- compattezza del codice prodotto nel linguaggio della macchina MI.
Tornando alla Fig. 1, notiamo che la pura interpretazione e la pura compilazione si hanno nei casi estremi caratterizzati rispettivamente dal fatto che la MI coincida con la macchina ML o la macchina HOST.
Un esempio concreto di applicazione di questo schema si ha per il linguaggio di programmazione
Java.
In questo caso, la macchina intermedia MI è la JVM
(Java Virtual Machine1), il cui linguaggio è detto Bytecode, mentre il
Run-Time System viene detto Java RunTime Enviroment. Per quanto riguarda la macchina HOST
,
nella pratica si hanno diverse realizzazione: dal PentiumII all'UltraSPARC, al PicoJavaII.
Non necessariamente la realizzazione di ML sulla macchina intermedia deve essere compilativa. Ci possono essere svariati motivi per avere sia ML che la macchina intermedia realizzati entrambi per interpretazione.
Nello sviluppo dei nostri sistemi di calcolo in genere il procedimento descritto
viene generalizzato, portando ad insieme di livelli di macchine astratte che si
frappongono fra la macchina realizzata in hardware e la macchina astratta del
"livello" utente, che potrebbe essere quella corrispondente ad un HLL
o ad un particolare applicativo (per esempio il programma "Office" o il sistema di
gestione utilizzato dalla vostra banca altro non sono che particolari
macchine astratte).
Gli scopi di tale stratificazione sono molteplici:
gestire la complessita' di progettazione, aumentare la flessibilita' del sistema ecc.
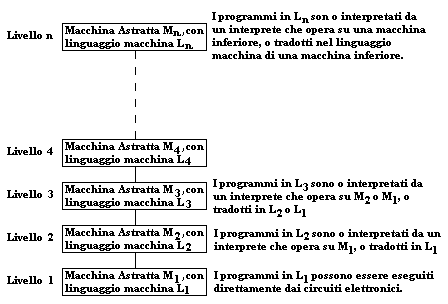 |
Il livello più basso rappresenta il computer reale e il linguaggio macchina che esso è in grado di eseguire direttamente. Ciascuno dei livelli superiori rappresenta una macchina astratta, i cui programmi devono essere o tradotti in termini di istruzioni di uno dei livelli inferiori (non necessariamente del livello immediatamente al di sotto), o interpretati da un programma che gira su di una macchina astratta di livello strettamente inferiore.
È da notare che nella pratica non è raro che un livello realizzi una
macchina astratta che non copre del tutto il livello sottostante ma ne potenzia alcune
delle caratteristiche, lasciandone trasparire del tutto altre.
E possibile cioe' che alune delle componenti della macchina siano esattamente
quelle della macchina ospite, mentre altre siano completamente diverse o magari
delle semplici estensioni. Nella seguente figura e' shematizzata la possibilita'
di una macchina, per esempio hardware, sulla quale e' realizzata un'altra macchina attraverso
emulazione via firmware solo di alcune sue componenti. Su quest'ultima e' poi
realizzata una ulteriore macchina che ha alcune componenti realizzate in software,
mentre altre sono esattamente le stesse della macchina sottostante o di
quella del livello ancora inferiore.
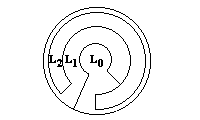 |
Un tipico computer moderno si può quindi pensare come una serie
di macchine astratte realizzate una sopra l'altra, ciascuna in grado di
fornire funzionalità via via più potenti.
Per chiarire le idee sulla complessità di questa decomposizione in
livelli, esaminiamo una possibile stratificazione dei comuni PC.
È da notare tuttavia che non è in alcun modo necessario che un sistema
di calcolo abbia un numero prefissato di livelli di astrazione: quella che segue
è solo una possibile soluzione, che mostra come ogni livello colmi la sua
parte di semantic gap.
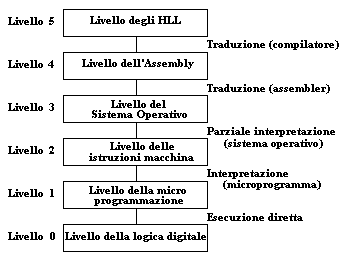 |
Nello schema non sono rappresentati i livelli sottostanti la logica digitale.
Le componenti fondamentali del livello 0 sono le cosiddette porte logiche (GATES): a partire da raggruppamenti di esse si formano i registri e le memorie. Le GATES sono dispositivi elettronici che, pur appartenendo al mondo analogico, costituiscono il ponte verso il mondo digitale, poichè esse tipicamente realizzano funzionalità (Not, And, Or, ...) che sono ben formalizzabili in termini di una teoria discreta nota come Algebra di Boole.
Collezioni di registri e circuiti digitali che realizzano funzionalità
aritmetico-logiche sono alla base del livello 1. Qui troviamo altri elementi
di interesse come il datapath e le strutture che presiedono al suo
controllo.
A questo livello inizia a diventare chiara l'idea di flusso di
informazione poichè sequenze di bit viaggiano da una componente all'altra
(della macchina astratta di questo livello) venendo eventualmente elaborate.
Il linguaggio del livello 2 è quello cui tipicamente ci si riferisce quando
si parla di linguaggio macchina di un certo computer. In termini tecnici,
questo livello è noto come ISA Level (Istruction Set Architecture Level);
tipiche istruzioni di questo livello sono ADD, MOVE, SUB, ...
Questo livello è di solito direttamente implementato in hardware
nelle architetture RISC, mentre e'
tipicamente è realizzato mediante interpretazione firmware nelle architetture
CISC. Questo significa che nelle architetture RISC il livello ISA e' in realta' il livello 1
(manca cioe' completamente il livello di microprogrammazione), mentre le architetture CISC
sono caratterizzate dalla presenza del livello di microprogrammazione.
Possiamo provare a fornire una definizione di livello microprogrammato nel seguente
modo: il livello 1 di un sistema di calcolo e' un livello di microprogrammazione
nel caso in cui la memoria programmi della macchina astratta realizzata in hw e' contenuta
sullo stesso chip che contiene la realizzazione della maggior parte delle componenti
(CPU) e non e' quindi realizzata, per esempio, nella RAM di Fig.1. Tale memoria programmi
e' estremamente veloce ma di dimensioni ridotte. Quest'ultima caratteristica
impedisce una realizzazione del livello sovrastaste per compilazione (non potremmo memorizzare
la traduzione di programmi anche minimamente complessi), ma
sicuramente ne permette una per interpretazione.
Tale realizzazione interpretativa del livello sovrastante, inoltre,
sara' estremamente efficiente proprio grazie al fatto che la memoria programmi
e' estremamente veloce (la fase di fech risulta molto piu' efficiente rispetto ad una realizzazione della memoria programmi
sulla RAM).
Il livello 3 evidenzia quella caratteristica precedentemente notata di non
coprire del tutto i livelli sottostanti: si tratta del livello del Sistema
Operativo (SO).
In esso la maggior parte delle istruzioni dell'ISA level sono
disponibili tali e quali; sono inoltre presenti nuove operazioni, che
consentono un livello di astrazione notevolmente più alto nell'ambito della
gestione della memoria e del flusso di controllo.
Tre delle principali funzionalità offerte dal Sistema Operativo sono:
- il concetto di FILE: a questo livello si realizza il salto qualitativo verso una memoria molto strutturata e organizzata gerarchicamente (File System) in cui informazioni complesse possono essere immagazzinate e recuperate con grande facilità
- la MEMORIA VIRTUALE: il Sistema Operativo offre ai livelli di astrazione superiore una macchina astratta con una quantità di memoria principale di gran lunga superiore a quella effettiva, liberando così il programmatore dai limiti fisici derivanti dalla particolare dotazione della macchina;
- l'astrazione di PROCESSO e il MULTITASKING: la possibilità di avere più
"pezzi" di programma (processi) in esecuzione indipendente e
(pseudo-)parallela è una delle caratteristiche che si è andata affermando
negli anni; è tale meccanismo che rende possibili funzionalità quali la
stampa in background o la garbage collection, etc.
Questo in linea di principio significa che il livello del Sistema Operativo in realta' puo' mettere a disposizione non una singola, ma molteplici macchine astratte.
La programmazione dei livelli introdotti fino a questo momento è
tipicamente compito di una cerchia ristretta di programmatori (i cosiddetti
sistemisti), poichè si tratta di macchine astratte che sono state ideate non perchè
interessanti in sè, ma in quanto necessarie per riuscire a gestire la
complessità dell'implementazione delle macchine astratte di livello superiore.
Il livello 4 segna quindi una rottura con i livelli precedenti: si tratta
del livello dell'assembly, il primo che presenti qualche caratteristica
(sebbene elementare) dei linguaggi di programmazione moderni (uso di
etichette, mnemonici per le istruzioni, presenza di macro, variabili
globali, procedure, etc...).
Tipicamente il livello 4 è realizzato sulle
macchine sottostanti mediante il meccanismo di traduzione realizzato da un
pezzo software (tipicamente scritto in ISA level language) noto come
ASSEMBLER.
tale livello si puo' definire come il piu' basso utilizzabile dal programmatore
di applicazioni eseguite dal sistema di calcolo.
Ad ogni modo è al livello 5 che entrano in gioco gli HLL: C, Java, C++, Haskell, Prolog, etc... Si tratta del livello più vario, dove troviamo tutte le possibili soluzioni implementative, anche per macchine astratte relative allo stesso linguaggio: ad esempio, esistono varianti sia interpretate che compilate del BASIC.
Come accennato in precedenza l'avvento di Java ha portato alla nascita di un livello
intermedio tra quelli del linguaggio ad alto livello e quello dell'assembly. Infatti
prima di
essere eseguiti, i programmi Java vengono tradotti in bytecode, ovvero nel
linguaggio macchina della Java Virtual Machine (JVM), che è
realizzata mediante interpretazione sui livelli sottostanti; successivamente saranno i
bytecode così ottenuti che verranno eseguiti sulla JVM.
I vantaggi di questa tecnica hanno recentemente portato alla implementazione
di molti linguaggi di programmazione (anche non Object Oriented) sulla JVM,
piuttosto che sui livelli 2-3-4: sostanzialmente la JVM si sta affermando
come macchina astratta standard all'interno della stratificazione tipica dei moderni
sistemi di calcolo.
Teniamo a precisare ancora una volta che i livelli appena descritti sono solo una tra le infinite possibilita' teoriche di strutturazione a livelli di un sistema di calcolo.
Programmazione delle Macchine Astratte
Riguardo la programmazione
e' talvolta possibile imbattersi (sempre piu' raramentente, per fortuna)
in affermazioni del seguente tipo:
Una programmazione consapevole ed adeguata per una particolare realizzazione di una macchina astratta e' possibile solo se l'utente conosce non solo la struttura della macchina astratta, ma anche quali componenti sono stati realizzati direttamente in hardware, quali emulati, quali interpretati. Infatti, scegliere un modo piuttosto che un altro di realizzare un algoritmo puo' risolversi in un guadagno di prestazioni, dovuto alla maggiore efficienza della realizzazione di alcune componenti della macchina astratta rispetto ad altri.
Gia' il fatto che questa sia una affermazione eccessivamente generica (che non fa cioe' riferimento a particolari contesti in cui poter essere utilizzata) dovrebbe insospettirci. L'Informatica e' la metafora della vita e nella vita non si puo' fare alcuna affermazione che sia valida a prescindere da specifici contesti.Ergo, e' possibile che in particolari contesti l'affermazione citata possa esser vera (pensiamo per esempio al caso di programmare una macchina astratta corrispondente al sistema di controllo della temperatura del nocciolo di una centrale atomica; ovviamente bisogna sfruttare al massimo tutte le possibilita' di velocizzare la routine che, identificato un insolito aumento di temperatura, metta in moto tutte le procedure di sicurezza). In generale pero' sappiamo che non esiste solo la velocita' di esecuzione di un programma come unico parametro di valutazione; per esempio c'e' anche la trasportabilita' di un programma. Un programma che abbia buone prestazioni solo perche' fa affidamento si certe caratteristiche della realizzazione della macchina astratta su cui gira, potrebbe avere prestazioni scadentissime su altre realizzazioni della stessa macchina. Questa considerazione e' ancora piu' importante se si considera' come sia sempre piu' rilevante oggi il concetto di codice mobile.
In generale quindi dobbiamo dire che nel programmare una macchina astratta dobbiamo far riferimento solo alla sua specifica, non alla sua realizzazione.
1. E' bene tener presente la possibile ambiguita' che potrebbe generare questo nome. La Java Virtual Machine infatti non e' la macchina astratta corrispondente al linguaggio JAVA, bensi' la macchina intermedia per JAVA.
| Prev | Top | Next |