Esercizi su Pipelining e Architetture Parallele
La maggior parte sono relativi a programmi di anni precedenti
Esercizio 1
Si individuino i conflitti e i conseguenti stalli della pipeline nella
seguente sequenza di istruzioni, ipotizzando una pipeline di 5 fasi:
SUB R2,R1,R3
AND R4,R2,R5
OR R8,R2,R6
ADD R9,R4,R2
SLT R1,R6,R7
Soluzione.
Esercizio 2
Si individui il conflitto di dati nel seguente codice,
supponendo di avere una pipeline a 5 fasi:
/reg.R2 contiene l'indirizzo di V[k]
LW R15,0(R2) /reg.R15 := V[k]
LW R16,4(R2) /reg.R16 := V[k+1]
SW R16,0(R2) / V[k] := reg.R16
SW R15,4(R2) / V[k+1] := reg.R15
e si riordinino le istruzioni per evitare il maggior numero di stalli
o di disfacimento delle operazioni.
(LW = Load Word; SW = Store Word)
Soluzione.
Esercizio 3
Si supponga che in una macchina le istruzioni LOAD e JUMP necessitino
di bloccare il processo di pipeline per n cicli di clock (una fase
del processo di pipeline prende un ciclo di clock).
Sapendo che una frazione L di tutte le istruzioni sono LOAD e una frazione J
sono jump, a quale rapporto della velocita' intera lavora la macchina?
Soluzione.
Esercizio 4
Considerando un'architettura che utilizza il pipeline, si dica se ciascuna delle seguenti
affermazioni e' vera o falsa, o si discuta in quali contesti potrebbe essere vera o falsa.
- In generale, ad ogni istante, la CPU sta eseguendo contemporaneamente piu' istruzioni.
- Il parallelismo e' ottenuto avendo a disposizione diversi Program Counters per lo
stesso programma.
- L'obiettivo di eseguire, in media, una istruzione per ogni ciclo di CPU puo' essere
solo avvicinato, ma mai raggiunto pienamente.
- Le operazioni di LOAD rendono piu' complessa la gestione del pipelining.
- Le operazioni di STORE rendono piu' complessa la gestione del pipelining.
- Le operazioni di salto condizionato rendono piu' complessa la gestione del pipelining.
Soluzione. (By Peppe Morreale)
Esercizio 5
Fare gli esercizi 29, 30, 31 e 32 del Capitolo 4 del Tanenbaum.
Soluzione del 30. (By S. Fede)
Soluzione del 31. (By Peppe Monreale)
Esercizio 6
Descrivere brevemente il funzionamento della Istruction Fetch Unit del Mic-2
Soluzione.
Esercizio 7
(Anni Precedenti)
Fare gli esercizi 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 17, 20, 21, 22, 23 del Capitolo 8 del Tanenbaum.
Soluzione 7.2. (By Max Salfi)
Soluzione 7.3. (By Max Salfi; Giorgio Stampa)
Soluzione 7.7. (By M. Firrincieli)
Esercizio 8
(Anni Precedenti)
Cos'e' un algoritmo di routing? Quando un algoritmo di questo tipo si dice statico?, quando dinamico?
Il dimensional routing algorithm e' un algoritmo di routing senza deadlock usato per
griglie rettangolari. Quali nodi si attraversano utilizzando questo algoritmo per andare dal nodo
(3,7,5) a quello (6,9,8) in una griglia tridimensionale?
Soluzione.
Esercizio 9
(Anni Precedenti)
Nel contesto delle reti di interconnessione (interconnection networks),
dire cosa si intende per:
Diameter (diametro)
Bisection bandwidth (bisezione dell'ampiezza di banda)
Dimensionality (dimensionalita')
Aggregate bandwidth.
Soluzione.
Esercizio 10
(Anni Precedenti)
Cosa si intende con Shared memory (memoria condivisa)?
In sistemi organizzati a livelli la memoria condivisa puo' essere realizzata in
uno qualsiasi dei livelli (hardware, operating system, application..)?
Discutere.
Esercizio 11
(Anni Precedenti)
Con semantica della memoria si intende un "contratto", un insieme di regole da seguire,
tra il software e la memoria hardware. Tali regole prendono il nome di
modelli di consistenza. Per quali tipo di macchine ha senso parlare di
modelli di consistenza della memoria? Potete descrivere qualche modello di consistenza?
Soluzione.
Esercizio 12
Cosa si intende per speculative execution (esecuzione speculativa)?
Il Pentium II "supporta" la speculative execution? (Anni Precedenti)
Soluzione.
Esercizio 13
L'architettura IA-64 utilizza una tecnica chiamata predication,
che permette di ridurre il numero di salti condizionati e che
permette di sfruttare bene la potenza delle pipeline.
Dire sinteticamente in cosa consiste.
Soluzione (by Valentina Campisi)
Esercizio 14
(Anni Precedenti)
Una rete di interconnessione e' un grafo formato da che possiamo rappresentare formalmente
un insieme di nodi (Nodes) ed un insieme di archi (Links) che collegano
i nodi. Se consideriamo grafi non orientati, l'insieme Links degli archi puo'
venire rappresentato formalmente da un insieme di
sottoinsiemi di cardinalita' 2 di elementi di Nodes.
Un arco che collega i nodi i e j sara' quindi denotato dall'insieme {i,j}.
Supponendo, per semplicita', di considerare solo reti con insiemi di nodi di
cardinalita' pari, scrivere una domanda abbastanza intelligente, la cui risposta sia:
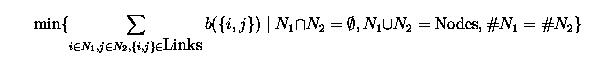
dove b((i,j)) indica la bandwidth (ampiezza di banda) del link {i,j} e # indica la
cardinalita' di un insieme.
Esercizio 14
(Anni Precedenti)
La legge di Amdahl dice che
n
Speedup = -------------
1 + (n-1)f
Che cosa indica f ?
Come si ottiene l'espressione data? (se non si ricorda bene dirlo anche in modo
orientativo)
Esercizio 15
Prendete in considerazione la figura 4-43 del Testo, che riguarda un esempio di possibile
funzionamento di una CPU superscalare con inizio e completamento in ordine.
Spiegare brevemente in dettaglio cosa descrive la figura ed il significato delle
sue varie parti.
Quale vantaggi si otterrebbero nell'esempio fornito dalla figura se
il completamento potesse essere fuori ordine?
Esercizio 16
Per permettere il funzionamento della Pipeline del picoJavaII, le istruzioni JVM
vengono classificate in base al loro comportamento. In particolare alcune
vengono classificate come non raggruppabili (Nonfoldable).
Per cosa utilizza tale classificazione la Pipeline del picoJavaII?
Esercizio 17
(Anni Precedenti)
Che cosa e' una tecnica di Predizione di Salto Statica (Static Branch Prediction)?
E Dinamica (Dynamic)?
Dire come funziona in genere la tecnica di predizione dinamica con un bit di predizione.
Perche' quella con due bit di predizione e' migliore? Come funziona?
Esercizio 18
Consideriamo un linguaggio macchina in cui sia presente l'istruzione JMPIFEQZ R label,
il cui significato sia: salta a label se il valore nel registro R e' zero.
Supponiamo ora di avere un programma che contenga un ciclo che fa eseguire un certo
numero di volte il codice seguente:
ISTR1
(*) JMPIFEQZ R1 L1
ISTR2
L1: ISTR3
ISTR4
Supponiamo che il programma venga eseguito su una macchina con pipeline
che utilizza la tecnica della predizione dinamica dei salti, con una
History Table con due bit di predizione.
In quanto segue, per ogni ciclo i (i=1,..6) sono indicati i valori
assunto dal registro R1 quando l'istruzione (*) viene eseguita.
Ricopiare quanto scritto sotto aggiungendo il valore dei due bit
di predizione per l'istruzione (*) dopo la sua esecuzione
e l'informazione riguardo l'esecuzione corretta o meno del salto.
Prima del ciclo 1 supporre che i bit di predizione per (*) siano 00.
| Ciclo | Contenuto di R1 | Prediction bits
per l'istruzione (*)
| Salto eseguito
correttamente? |
| 1 | 0 | _ _ | ______ |
| 2 | 3 | _ _ | ______ |
| 3 | 0 | _ _ | ______ |
| 4 | 0 | _ _ | ______ |
| 5 | 1 | _ _ | ______ |
| 6 | 0 | _ _ | ______ |
Soluzione.
Esercizio 19
Si completi la seguente tabella rappresentante l?Esecuzione in Ordine
da parte di una CPU superscalare con 2 unita? di decodifica.
Si evidenzino le eventuali dipendenze.
Si supponga che + impieghi 2 cicli per essere eseguita e che * ne impieghi
3.
Nota. Nell'Esecuzione in Ordine le istruzioni sono iniziate (Issued) in
ordine e completate (Retired) in ordine.
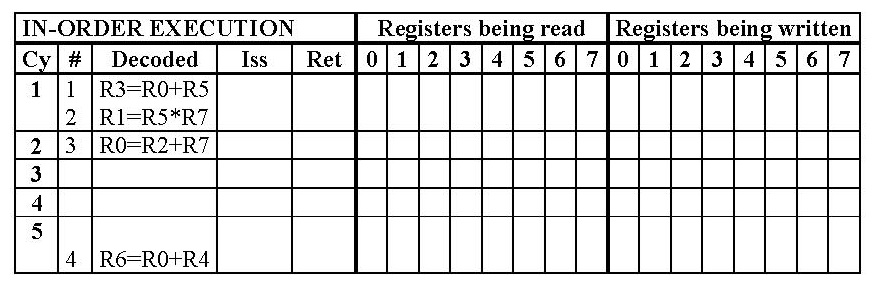
Soluzione.
Esercizio 20
In un processore con parallelismo di tipo pipeline,
cosa si intende per latenza (latency) e larghezza di banda del
processore (processor bandwidth)?
Fare le dovute ipotesi
e fornire latenza e larghezza di banda per un processore
pipeline con n fasi e ciclo di clock di T nsec.
Cos'e' un processore superscalare? e' anch'esso di tipo pipeline?
{kind=link}